
Why is AI hard and Physics simple?
Authors
Daniel A. Roberts
Abstract
We discuss why AI is hard and why physics is simple. We discuss how physical intuition and the approach of theoretical physics can be brought to bear on the field of artificial intelligence and specifically machine learning. We suggest that the underlying project of machine learning and the underlying project of physics are strongly coupled through the principle of sparsity, and we call upon theoretical physicists to work on AI as physicists. As a first step in that direction, we discuss an upcoming book on the principles of deep learning theory that attempts to realize this approach.
Concepts
The Big Picture
Here’s a puzzle that should bother you more than it probably does: the same civilization that can predict the precise moment an electron changes energy levels, to eleven decimal places, cannot reliably explain why a neural network learned to recognize cats. We can split atoms and model the birth of the universe, but we mostly don’t know why deep learning works. Physics: comprehensible. Intelligence: mysterious. Why?
That’s the question MIT theoretical physicist Daniel A. Roberts takes on in this essay. His answer isn’t merely philosophical. Roberts argues that the tools physicists have spent centuries developing, their instinct for finding hidden structure in apparent chaos, are exactly what AI needs. One principle connects both fields: sparsity, the idea that a small number of deep rules govern a vast range of phenomena and that finding those rules is the whole game.
The same reason physics is tractable (nature is sparse, governed by a small number of rules) is also why machine learning works at all.
How It Works
Roberts opens with the no-free-lunch theorem, a result from mathematical statistics that sounds like a death sentence for machine learning: if you average over all possible problems, no algorithm does better than random guessing.
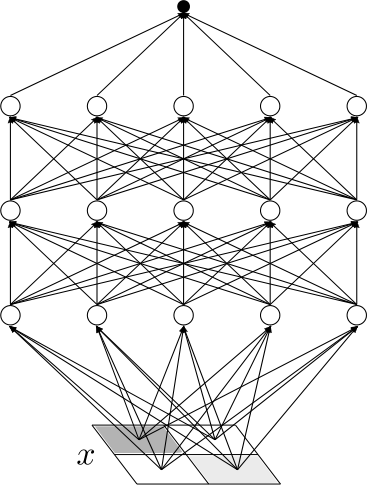
Think about images. An n-pixel black-and-white image is one of 2ⁿ possibilities. The number of ways to assign labels to all those images is 2^(2ⁿ), doubly exponential. For just 9 pixels, that’s more possible labeling schemes than atoms in the observable universe. And yet humans learn. Deep learning works. Cats get recognized.
The resolution is structure. Random labelings of random images are mathematically possible but humanly meaningless. Real tasks have deep regularities: cat images share features with other cat images, and labels correlate with those features. The actual functions describing meaningful phenomena occupy a tiny, structured corner of all possible functions. This is sparsity, and it’s the only reason generalization is possible at all.
Physics discovered this long ago. Effective field theory, one of the physicist’s sharpest tools, is sparsity in action: you don’t need to know every detail of a system to make accurate predictions. You identify the few relevant degrees of freedom and build your theory around them.
The Standard Model describes all known fundamental particles with roughly 20 parameters. Thermodynamics reduces the behavior of 10²³ molecules to temperature and pressure. Physics works because nature is sparse.
Machine learning does the same thing, whether it knows it or not. Training a neural network means fitting a model to data, which is what physicists do when they tune parameters to match experiment. Generalization works only when the target function has sparse structure the model can discover. Deep learning succeeds in part because hierarchical architectures mirror the hierarchical structure of physical reality: edges compose into shapes, shapes into objects, objects into scenes.
The difference is that physics has a mature theoretical framework for understanding when and why its models work. Machine learning mostly doesn’t. Not yet.
Why It Matters
Roberts is making a disciplinary argument, not just a mathematical one. He’s urging theoretical physicists to enter AI not as consultants but as physicists, bringing their comfort with approximation and scaling, their nose for the right variables, and above all their habit of cycling between theory and experiment.
The physicist doesn’t demand a rigorous proof before engaging with a problem. She builds intuition, makes predictions, tests them against data, and refines. That cycle is what deep learning theory needs.
The stakes are real. AI systems are embedded in consequential decisions, and we still lack a principled understanding of what makes them work or fail. Roberts wants a genuine theoretical physics of deep learning: predictive, falsifiable, built from first principles with controlled approximations validated against real networks.
The connection to physics isn’t just metaphorical, either. Mean-field theory, the replica method, and the renormalization group are all finding direct application in understanding neural network training and generalization. The influence runs both ways: AI problems are reshaping how physicists think about complexity.
Roberts’ prescription: bring physicists into AI to work as physicists, not just as mathematicians. The world is sparse, and that hard-won insight from physics could be what’s missing from a real science of intelligence.
IAIFI Research Highlights
Roberts argues that physics and machine learning share deep common structure through sparsity. AI theory is a natural extension of the physicist's program of finding simple rules for complex phenomena.
The essay offers a conceptual framework for why deep learning succeeds despite the no-free-lunch theorem, pointing toward a physics-inspired theoretical foundation for more principled, interpretable AI.
Effective field theory, statistical mechanics, and renormalization group methods apply directly to understanding neural networks, extending theoretical physics into the study of artificial intelligence.
Roberts previews a book developing first-principles deep learning theory using physicist methodology; the paper is available at [arXiv:2104.00008](https://arxiv.org/abs/2104.00008).
Original Paper Details
Why is AI hard and Physics simple?
2104.00008
Daniel A. Roberts
We discuss why AI is hard and why physics is simple. We discuss how physical intuition and the approach of theoretical physics can be brought to bear on the field of artificial intelligence and specifically machine learning. We suggest that the underlying project of machine learning and the underlying project of physics are strongly coupled through the principle of sparsity, and we call upon theoretical physicists to work on AI as physicists. As a first step in that direction, we discuss an upcoming book on the principles of deep learning theory that attempts to realize this approach.