
The Unreasonable Ineffectiveness of the Deeper Layers
Authors
Andrey Gromov, Kushal Tirumala, Hassan Shapourian, Paolo Glorioso, Daniel A. Roberts
Abstract
How is knowledge stored in an LLM's weights? We study this via layer pruning: if removing a certain layer does not affect model performance in common question-answering benchmarks, then the weights in that layer are not necessary for storing the knowledge needed to answer those questions. To find these unnecessary parameters, we identify the optimal block of layers to prune by considering similarity across layers; then, to "heal" the damage, we perform a small amount of finetuning. Surprisingly, with this method we find minimal degradation of performance until after a large fraction (up to half) of the layers are removed for some common open-weight models. From a scientific perspective, the robustness of these LLMs to the deletion of layers implies either that current pretraining methods are not properly leveraging the parameters in the deeper layers of the network or that the shallow layers play a critical role in storing knowledge. For our study, we use parameter-efficient finetuning (PEFT) methods, specifically quantization and Low Rank Adapters (QLoRA), such that each of our experiments can be performed on a single 40GB A100 GPU.
Concepts
The Big Picture
Imagine building a 70-story skyscraper, only to discover that you could quietly demolish floors 30 through 65 and the building still stands. Not just stands: it passes every safety inspection you throw at it. That’s roughly what researchers from Meta FAIR, MIT, and collaborators found when they started slicing through large language models layer by layer.
Large language models like Llama and Mistral are stacked structures: dozens of nearly identical processing layers, each digesting text a little further before passing it along. The conventional wisdom is that depth is what makes these models powerful. More layers means more complex reasoning, a richer internal model of language, deeper “understanding.” But what if most of those layers aren’t actually doing much?
That’s the question this paper, published at ICLR 2025, sets out to answer. By surgically removing consecutive groups of layers and applying a brief retraining step, the researchers showed that many of the deeper layers in today’s best publicly available models are surprisingly expendable. It calls into question how we train these systems in the first place.
Key Insight: You can strip away up to half the layers of a 70-billion-parameter model like Llama-2-70B while preserving most of its question-answering performance. Current training methods may waste enormous computational resources on redundant depth.
How It Works
The pruning strategy is simple. Rather than removing random layers or naively cutting from the end, the team developed a principled method to find which layers are most redundant.
The core idea exploits the residual stream structure of transformers. Each layer adds its output to a running “stream” of information rather than fully transforming it. If a layer’s contribution is small (the data coming out looks almost identical to the data going in) then removing it should cause minimal disruption.
To measure this, the researchers compute the angular distance between the input and output of each layer: how much the representation changed, expressed as an angle in high-dimensional space. Think of it like comparing two arrows. If they point in nearly the same direction, the layer barely changed anything.
The process:
- Measure similarity: For a candidate block of n consecutive layers, compute the angular distance between the representation entering the block and the representation leaving it.
- Find the minimum: Sweep across all possible starting positions and pick the block where this angular distance is smallest. These are the layers doing the least work.
- Remove the block: Physically delete those layers from the model.
- Heal the damage: Fine-tune the pruned model using QLoRA (Quantized Low-Rank Adapters), a lightweight retraining method that adjusts only a small fraction of the model’s weights to compensate for the missing layers.
The entire healing step runs on a single 40GB A100 GPU. Not exotic hardware, just the kind of setup a well-funded research lab or advanced graduate student might have access to.
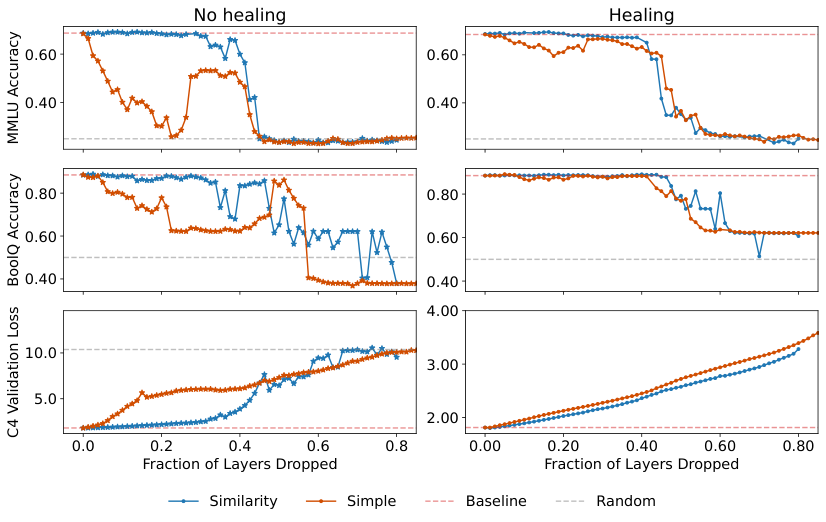
Angular distance maps make the pattern obvious: deeper layers consistently show smaller distances to their neighbors than shallower ones. Internal representations barely change as information flows through the final third of the network. This points to an even simpler heuristic: just start removing layers from the deepest end. It works almost as well as the full similarity search.
For Llama-2-70B, the flagship result, performance on standard question-answering benchmarks like MMLU and BoolQ stays flat as layers are removed until roughly the 40–50% pruning mark, where it falls off a cliff. Language modeling loss on C4 degrades more gradually, holding closer to baseline even at aggressive pruning levels after healing. Plateaus followed by sudden collapses, not gradual declines. That looks like genuine redundancy.
Why It Matters
The title borrows from physicist Eugene Wigner’s famous essay on “the unreasonable effectiveness of mathematics,” flipped on its head. The deeper layers are unreasonably ineffective. That should bother anyone who cares about how we build AI systems.
There are two ways to read this. The optimistic version: these models have more capacity than current training methods know how to fill. The deeper layers are undertrained, not inherently useless, and better training recipes, longer runs, or different architectures could unlock real gains without adding a single parameter.
The more sobering version: shallow layers do most of the heavy lifting for storing factual knowledge, and depth beyond a certain point offers diminishing returns no matter how you train. Either way, the trillion-parameter scaling race may need to reckon with this.
Compressed models that keep most of their capability but run in half the memory make deployment on commodity hardware realistic. Inference gets faster, costs drop sharply. The single-GPU fine-tuning requirement puts this within reach of the broader research community, not just labs with massive clusters.
What’s still unclear: does this hold for reasoning-focused models trained with reinforcement learning? Are there tasks like complex multi-step math or long-form reasoning where the deeper layers actually earn their keep? And can training procedures be redesigned from the start to use depth more efficiently?
Bottom Line: Half the layers of a 70B model can be removed with minimal performance loss. This unsettles basic assumptions about depth in neural networks and points toward dramatically cheaper inference.
IAIFI Research Highlights
This work takes a physicist's approach to neural networks: remove parts and measure what breaks. It treats the question of where knowledge lives in a model as an empirical problem, not an architectural assumption.
The paper provides a practical, single-GPU method for compressing large language models by up to 50% with minimal benchmark degradation. Large-model compression becomes accessible, and the assumption that deep architectures are always necessary takes a hit.
Framing layer pruning through residual stream dynamics and angular similarity offers a new empirical handle on the representational geometry of neural networks, with clear parallels to theoretical physics methods for understanding learning systems.
Key open questions include whether reasoning-intensive models show the same layer redundancy and whether training objectives can be redesigned to use depth more efficiently. The paper is available as [arXiv:2403.17887](https://arxiv.org/abs/2403.17887) and was published at ICLR 2025.
Original Paper Details
The Unreasonable Ineffectiveness of the Deeper Layers
2403.17887
Andrey Gromov, Kushal Tirumala, Hassan Shapourian, Paolo Glorioso, Daniel A. Roberts
How is knowledge stored in an LLM's weights? We study this via layer pruning: if removing a certain layer does not affect model performance in common question-answering benchmarks, then the weights in that layer are not necessary for storing the knowledge needed to answer those questions. To find these unnecessary parameters, we identify the optimal block of layers to prune by considering similarity across layers; then, to "heal" the damage, we perform a small amount of finetuning. Surprisingly, with this method we find minimal degradation of performance until after a large fraction (up to half) of the layers are removed for some common open-weight models. From a scientific perspective, the robustness of these LLMs to the deletion of layers implies either that current pretraining methods are not properly leveraging the parameters in the deeper layers of the network or that the shallow layers play a critical role in storing knowledge. For our study, we use parameter-efficient finetuning (PEFT) methods, specifically quantization and Low Rank Adapters (QLoRA), such that each of our experiments can be performed on a single 40GB A100 GPU.