
The Quantization Model of Neural Scaling
Authors
Eric J. Michaud, Ziming Liu, Uzay Girit, Max Tegmark
Abstract
We propose the Quantization Model of neural scaling laws, explaining both the observed power law dropoff of loss with model and data size, and also the sudden emergence of new capabilities with scale. We derive this model from what we call the Quantization Hypothesis, where network knowledge and skills are "quantized" into discrete chunks ($\textbf{quanta}$). We show that when quanta are learned in order of decreasing use frequency, then a power law in use frequencies explains observed power law scaling of loss. We validate this prediction on toy datasets, then study how scaling curves decompose for large language models. Using language model gradients, we automatically decompose model behavior into a diverse set of skills (quanta). We tentatively find that the frequency at which these quanta are used in the training distribution roughly follows a power law corresponding with the empirical scaling exponent for language models, a prediction of our theory.
Concepts
The Big Picture
Every few months, a new and more powerful AI language model arrives, and researchers scramble to explain why it can suddenly do things its predecessor couldn’t. GPT-4 could write working code. Earlier models couldn’t. Somewhere between “small” and “large,” something clicked.
Here’s the puzzle: if you plot overall performance against model size, the curve is perfectly smooth, following what mathematicians call a power law. Each doubling of model size produces the same proportional improvement. No surprises. Yet zoom in on specific skills, like solving math problems or translating rare languages, and you see discrete jumps. Capabilities appear out of nowhere, as if a switch got flipped. The two pictures look nothing alike, and for years nobody had a unified explanation for both.
A team at MIT and IAIFI now has one. In a paper published at NeurIPS 2023, Eric Michaud, Ziming Liu, Uzay Girit, and Max Tegmark propose the Quantization Model of neural scaling. Their framework derives both the smooth power law and sudden emergence from a single set of assumptions about how knowledge is structured inside neural networks.
Key Insight: Neural networks don’t learn continuously. They learn in discrete chunks called quanta, each representing one indivisible skill or fact. The smooth scaling law is just an average over countless tiny discrete jumps, and “emergent abilities” are what individual quanta look like up close.
How It Works
The core idea, which the authors call the Quantization Hypothesis, is that the knowledge required to predict text breaks down into a large number of discrete, indivisible units called quanta. You either have a given quantum or you don’t. Examples include incrementing a numbered list, continuing a hex color code sequence, recognizing the syntax of a legal citation, or predicting line breaks in fixed-width text.
Not all quanta are equally useful. Some appear constantly in text (basic grammar); others appear rarely (formatting a specific chemical equation). Rank them by frequency and you get a Zipf distribution, the same power law pattern that governs word frequencies, city sizes, and income distributions.
This leads to a clean prediction. If models learn quanta in order of decreasing frequency, and those frequencies follow a power law, then the overall error rate should also fall as a power law with model size. Smooth scaling emerges not because learning is continuous, but because you’re averaging over thousands of discrete on/off events of varying magnitude. Think of water flowing through a pipe: perfectly smooth to the eye, but made of billions of individual bouncing molecules.
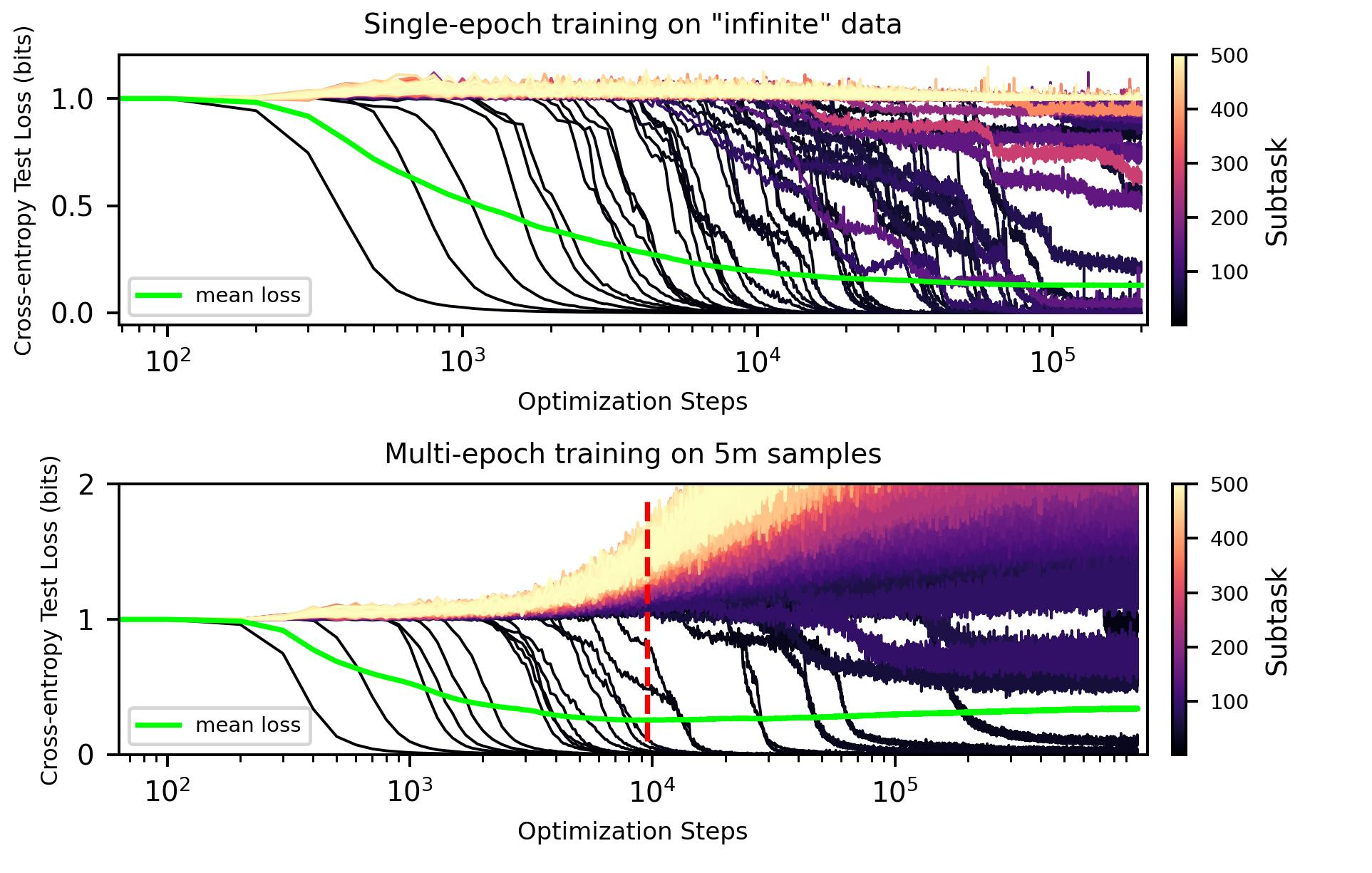
The team validates this on toy datasets where ground truth is known, synthetic text distributions where each skill is explicitly defined. Models learn quanta one by one in frequency order, and the resulting scaling curves match the theory.
Then they turn to real language models. To discover quanta in actual LLMs, they use model gradients, the signals that tell a network which way to adjust its weights during training. Training samples that produce similar gradient updates likely require the same underlying skill. Cluster the gradient similarities across a large sample of text and you get coherent groups, each one a candidate quantum.
Why It Matters
The clusters are revealing. One groups texts where the model must increment a numbered list, whether of song titles, legal clauses, or book chapters. Another captures the task of predicting line breaks in fixed-width formats across wildly different content. These quanta are genuinely universal: the same computational skill applies across many superficially different contexts, just as the theory predicts.
Do the discovered quanta obey the predicted frequency distribution? Roughly, yes. Skill clusters appear in training data at frequencies that follow a power law, and the exponent is consistent with the empirical scaling exponent for language models. The Zipfian structure that the theory requires to produce power law scaling is actually present in the training data.
The payoff goes beyond explaining scaling curves. If skills are discrete and enumerable, we could in principle catalog them. Instead of treating a model as an inscrutable black box, you’d have a structured inventory of what it “knows.”
That idea connects to mechanistic interpretability, the project of reverse-engineering the internal computations neural networks learn to perform. If knowledge is modular and universal, understanding large models becomes tractable in a way it wouldn’t be if everything were an undifferentiated blur.
There’s a historical parallel worth drawing out. Max Planck’s 1900 insight that energy comes in discrete chunks launched quantum mechanics. Michaud and colleagues apply the same logic to neural networks: smooth macroscopic behavior arises from underlying discrete structure. The standard tools of statistical physics, power law distributions and universality arguments, turn out to transfer directly.
Bottom Line: The Quantization Model unifies two of the most puzzling features of modern AI scaling, smooth power laws and sudden emergent abilities, by showing both follow from a Zipf-distributed collection of discrete skills learned one by one. It’s a physics-style theory for how neural networks organize their knowledge.
IAIFI Research Highlights
The paper takes conceptual tools straight from physics (discretization, universality, power law statistics) and turns them on the theory of neural network scaling. It's a direct application of physics reasoning to open questions in AI.
The Quantization Model offers a single theoretical explanation for both smooth scaling laws and emergent abilities. The gradient-based method for discovering discrete skills inside language models is a practical contribution in its own right.
Zipfian distributions in skill frequencies produce power law scaling, tying statistical physics and information theory to the empirical behavior of large language models.
If the framework holds up, it could eventually predict which capabilities will emerge at specific model scales before training begins, and inform the design of more interpretable architectures. The paper is available at [arXiv:2303.13506](https://arxiv.org/abs/2303.13506).
Original Paper Details
The Quantization Model of Neural Scaling
2303.13506
Eric J. Michaud, Ziming Liu, Uzay Girit, Max Tegmark
We propose the Quantization Model of neural scaling laws, explaining both the observed power law dropoff of loss with model and data size, and also the sudden emergence of new capabilities with scale. We derive this model from what we call the Quantization Hypothesis, where network knowledge and skills are "quantized" into discrete chunks ($\textbf{quanta}$). We show that when quanta are learned in order of decreasing use frequency, then a power law in use frequencies explains observed power law scaling of loss. We validate this prediction on toy datasets, then study how scaling curves decompose for large language models. Using language model gradients, we automatically decompose model behavior into a diverse set of skills (quanta). We tentatively find that the frequency at which these quanta are used in the training distribution roughly follows a power law corresponding with the empirical scaling exponent for language models, a prediction of our theory.