
The Dark Machines Anomaly Score Challenge: Benchmark Data and Model Independent Event Classification for the Large Hadron Collider
Authors
T. Aarrestad, M. van Beekveld, M. Bona, A. Boveia, S. Caron, J. Davies, A. De Simone, C. Doglioni, J. M. Duarte, A. Farbin, H. Gupta, L. Hendriks, L. Heinrich, J. Howarth, P. Jawahar, A. Jueid, J. Lastow, A. Leinweber, J. Mamuzic, E. Merényi, A. Morandini, P. Moskvitina, C. Nellist, J. Ngadiuba, B. Ostdiek, M. Pierini, B. Ravina, R. Ruiz de Austri, S. Sekmen, M. Touranakou, M. Vaškevičiūte, R. Vilalta, J. R. Vlimant, R. Verheyen, M. White, E. Wulff, E. Wallin, K. A. Wozniak, Z. Zhang
Abstract
We describe the outcome of a data challenge conducted as part of the Dark Machines Initiative and the Les Houches 2019 workshop on Physics at TeV colliders. The challenged aims at detecting signals of new physics at the LHC using unsupervised machine learning algorithms. First, we propose how an anomaly score could be implemented to define model-independent signal regions in LHC searches. We define and describe a large benchmark dataset, consisting of >1 Billion simulated LHC events corresponding to $10~\rm{fb}^{-1}$ of proton-proton collisions at a center-of-mass energy of 13 TeV. We then review a wide range of anomaly detection and density estimation algorithms, developed in the context of the data challenge, and we measure their performance in a set of realistic analysis environments. We draw a number of useful conclusions that will aid the development of unsupervised new physics searches during the third run of the LHC, and provide our benchmark dataset for future studies at https://www.phenoMLdata.org. Code to reproduce the analysis is provided at https://github.com/bostdiek/DarkMachines-UnsupervisedChallenge.
Concepts
The Big Picture
Imagine searching for a counterfeit bill in a pile of a billion real ones, but you’ve never seen a fake, and you have no idea what it might look like. That’s roughly the challenge physicists face at the Large Hadron Collider. Every second, the LHC produces millions of proton-proton collisions, each generating a cascade of particles recorded in exquisite detail.
The Standard Model of particle physics predicts what most of those collisions should look like. But somewhere in that ocean of data, there might be something extraordinary: a hint of dark matter, a new force, a particle no one has theorized yet. If you only search for things you already expect, you’ll never find what you didn’t imagine.
This is what drives model-independent searches, an approach that asks machine learning to play the skeptical detective: scan everything, assume nothing, flag whatever looks unusual. Physicists have wanted to apply this idea systematically at the LHC for years. Dreaming and doing, however, are different things.
To actually test such methods, you need a massive, standardized dataset and a fair way to compare dozens of competing algorithms. The Dark Machines Anomaly Score Challenge, a collaboration of over 40 researchers across three continents, delivers exactly that.
Key Insight: By creating a billion-event benchmark dataset and systematically evaluating 13 anomaly detection algorithms, the Dark Machines collaboration has produced the most extensive benchmark to date for automated, assumption-free new-physics searches at the LHC, clarifying which methods work, when, and why.
How It Works
The challenge begins with data, and a truly staggering amount of it. The team simulated more than 1 billion LHC collision events, corresponding to 10 inverse femtobarns (fb⁻¹, a unit measuring integrated luminosity) at 13 TeV center-of-mass energy. These aren’t toy examples; they’re full-fidelity simulations of the Standard Model background, the constant flood of “ordinary” physics that any anomaly detector must learn to see past. On top of this background, the team injected 17 different BSM (beyond Standard Model) signal samples representing hypothetical new-physics scenarios.
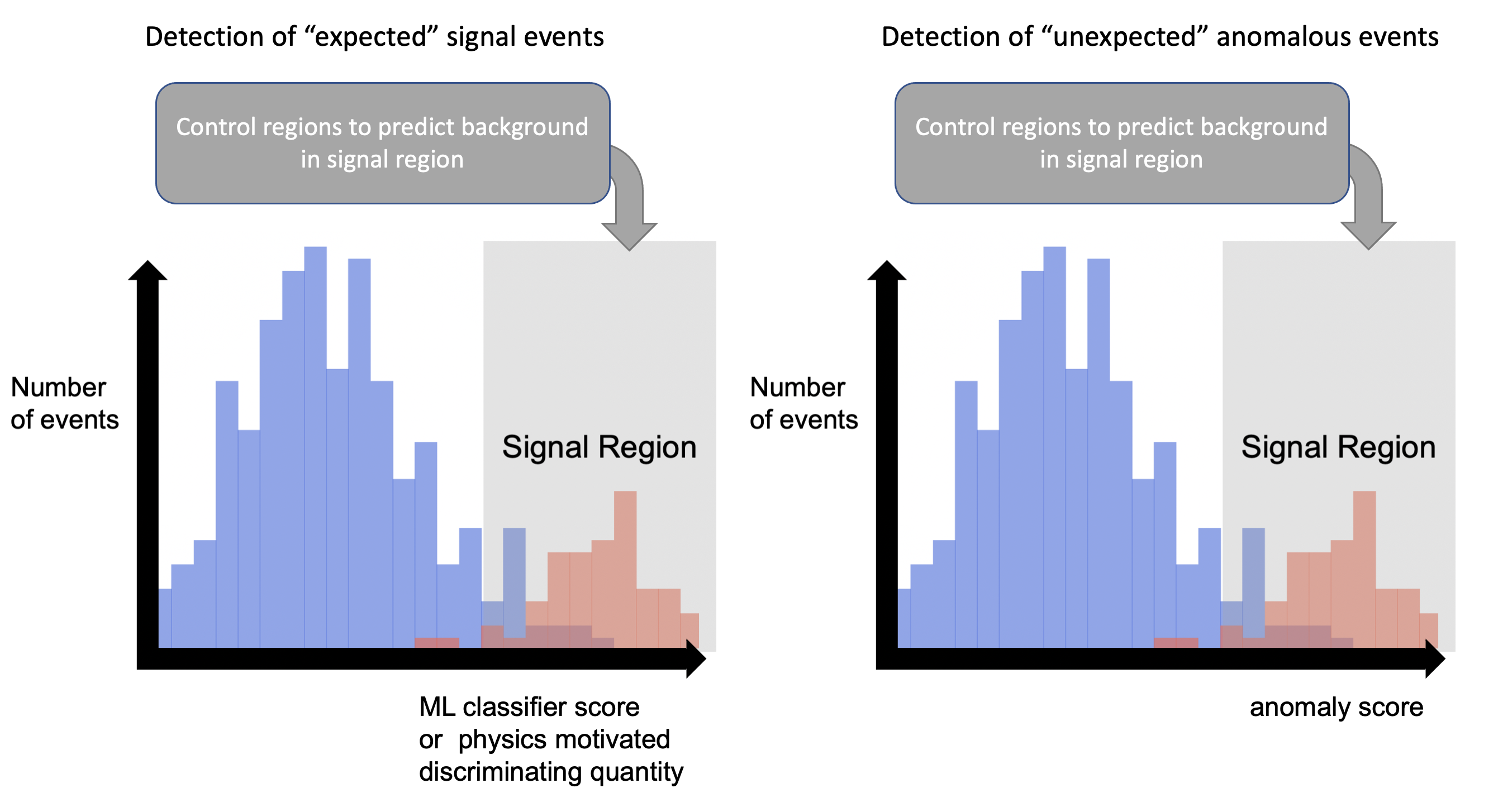
The core concept the challenge tests is the anomaly score: a number assigned to each collision event quantifying how “weird” it looks compared to the baseline. Events with high anomaly scores are candidates for a model-independent signal region, a zone worth examining more closely, not because you know what you’re looking for, but because something there doesn’t fit. Performance was measured using two metrics:
- True Positive Rate (TPR) at a fixed false positive rate: how often does the algorithm catch real signal events while keeping background contamination low?
- Significance Improvement Characteristic (SIC): a curve showing how much statistical significance improves as you cut more aggressively on the anomaly score.
Thirteen algorithms competed, spanning a wide zoo of machine learning architectures. Autoencoders, neural networks trained to compress and then reconstruct events, dominated numerically. The idea is simple: train on Standard Model background, and events that reconstruct poorly get flagged as anomalies. Variants included Variational Autoencoders (VAEs), which learn a probabilistic latent representation, and Convolutional VAEs that process events as image-like structures.
The challenge also tested normalizing flows (which learn an explicit probability density over the data), kernel density estimation (a classical technique for estimating how densely populated different regions of data space are), Deep SVDD (which maps normal data onto a tight hypersphere in latent space, flagging anything that falls outside it), and hybrid models combining multiple approaches.
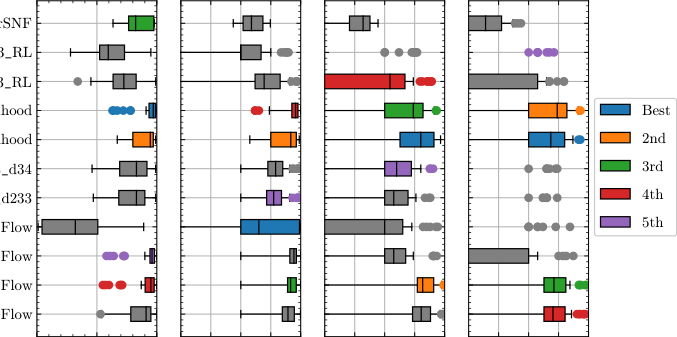
The results, shown as box-and-whisker plots across 17 signals and multiple analysis channels, show no clear winner. For some signals, particularly those producing distinctive high-energy particle showers called boosted jets, certain autoencoder variants achieve impressive significance improvements. For others, especially signals that differ only subtly from the background, most methods struggle.
Combining multiple algorithms often outperforms any individual method, a strong argument for ensemble approaches in future LHC analyses. The benchmark also included a “blinded” dataset whose signals were unknown to algorithm developers until after submission. This was a real test of generalization, not in-sample optimization.
Why It Matters
LHC searches have long operated under a basic constraint: you can only discover what you think to look for. Every traditional analysis is optimized for a specific signal hypothesis, meaning countless exotic possibilities may be hiding in plain sight. Unsupervised anomaly detection offers a way to loosen this constraint, letting the data itself point to interesting regions rather than waiting for theorists to go first.
The Dark Machines challenge also puts AI methods through an unusually tough test. Anomaly detection in particle physics may be one of the hardest use cases around: the “normal” class is extraordinarily complex and high-dimensional, signal-to-noise can be one part in a million, and a false positive isn’t just a misclassification but potentially years of misallocated experimental effort.
That no single method dominates, while hybrids show promise, matters beyond particle physics too. Anyone building anomaly detectors for real-world problems faces the same questions about when different algorithms succeed, when they fail, and whether combining them helps.
Bottom Line: The Dark Machines challenge establishes the first large-scale, standardized benchmark for unsupervised new-physics searches at the LHC, showing that while no single algorithm is a silver bullet, combining complementary methods can extend the reach of model-independent discovery at colliders.
IAIFI Research Highlights
This work combines unsupervised deep learning with experimental particle physics, building a framework for using AI to search for phenomena beyond current theory.
The challenge provides one of the most demanding real-world anomaly detection benchmarks available: a billion-event, high-dimensional dataset with known ground truth. It advances understanding of when and why different unsupervised algorithms succeed or fail.
By enabling model-independent signal regions at the LHC, this framework opens a systematic path to discovering new particles or forces that fall outside all currently theorized BSM models.
With the LHC continuing to accumulate data at record rates, the methods benchmarked here are becoming increasingly practical. The dataset and code are publicly available, and the paper ([arXiv:2105.14027](https://arxiv.org/abs/2105.14027)) is open for the community to build on.
Original Paper Details
The Dark Machines Anomaly Score Challenge: Benchmark Data and Model Independent Event Classification for the Large Hadron Collider
[arXiv:2105.14027](https://arxiv.org/abs/2105.14027)
T. Aarrestad, M. van Beekveld, M. Bona, A. Boveia, S. Caron, J. Davies, A. De Simone, C. Doglioni, J. M. Duarte, A. Farbin, H. Gupta, L. Hendriks, L. Heinrich, J. Howarth, P. Jawahar, A. Jueid, J. Lastow, A. Leinweber, J. Mamuzic, E. Merényi, A. Morandini, P. Moskvitina, C. Nellist, J. Ngadiuba, B. Ostdiek, M. Pierini, B. Ravina, R. Ruiz de Austri, S. Sekmen, M. Touranakou, M. Vaškevičiūtė, R. Vilalta, J. R. Vlimant, R. Verheyen, M. White, E. Wulff, E. Wallin, K. A. Wozniak, Z. Zhang
We describe the outcome of a data challenge conducted as part of the Dark Machines Initiative and the Les Houches 2019 workshop on Physics at TeV colliders. The challenged aims at detecting signals of new physics at the LHC using unsupervised machine learning algorithms. First, we propose how an anomaly score could be implemented to define model-independent signal regions in LHC searches. We define and describe a large benchmark dataset, consisting of >1 Billion simulated LHC events corresponding to $10~\rm{fb}^{-1}$ of proton-proton collisions at a center-of-mass energy of 13 TeV. We then review a wide range of anomaly detection and density estimation algorithms, developed in the context of the data challenge, and we measure their performance in a set of realistic analysis environments. We draw a number of useful conclusions that will aid the development of unsupervised new physics searches during the third run of the LHC, and provide our benchmark dataset for future studies at https://www.phenoMLdata.org. Code to reproduce the analysis is provided at https://github.com/bostdiek/DarkMachines-UnsupervisedChallenge.