
SymbolFit: Automatic Parametric Modeling with Symbolic Regression
Authors
Ho Fung Tsoi, Dylan Rankin, Cecile Caillol, Miles Cranmer, Sridhara Dasu, Javier Duarte, Philip Harris, Elliot Lipeles, Vladimir Loncar
Abstract
We introduce SymbolFit, a framework that automates parametric modeling by using symbolic regression to perform a machine-search for functions that fit the data while simultaneously providing uncertainty estimates in a single run. Traditionally, constructing a parametric model to accurately describe binned data has been a manual and iterative process, requiring an adequate functional form to be determined before the fit can be performed. The main challenge arises when the appropriate functional forms cannot be derived from first principles, especially when there is no underlying true closed-form function for the distribution. In this work, we develop a framework that automates and streamlines the process by utilizing symbolic regression, a machine learning technique that explores a vast space of candidate functions without requiring a predefined functional form because the functional form itself is treated as a trainable parameter, making the process far more efficient and effortless than traditional regression methods. We demonstrate the framework in high-energy physics experiments at the CERN Large Hadron Collider (LHC) using five real proton-proton collision datasets from new physics searches, including background modeling in resonance searches for high-mass dijet, trijet, paired-dijet, diphoton, and dimuon events. We show that our framework can flexibly and efficiently generate a wide range of candidate functions that fit a nontrivial distribution well using a simple fit configuration that varies only by random seed, and that the same fit configuration, which defines a vast function space, can also be applied to distributions of different shapes, whereas achieving a comparable result with traditional methods would have required extensive manual effort.
Concepts
The Big Picture
Trying to describe a mountain range’s shape with an equation is hard enough when you have some idea what family of functions to reach for. At the Large Hadron Collider, physicists face a version of this problem where nobody even knows what kind of equation to try. They need to model the “background,” the flood of ordinary collision events that can mimic signs of new physics, by fitting a function to a histogram of collision counts. Detector quirks, filtering choices, and layers of complex physics all warp the data’s shape in ways that can’t be derived from first principles. The result has been a lot of educated guessing, manual iteration, and trial-and-error.
A team of researchers has now built SymbolFit (arXiv:2411.09851), a framework that automates this entire process using symbolic regression, a machine learning approach that searches for the best functional form, not just the best parameters.
SymbolFit treats the mathematical form of the fitting function itself as something to be discovered, not assumed in advance. A machine finds good candidate equations from scratch while simultaneously estimating their uncertainties, so human guesswork drops out of the picture.
How It Works
Traditional regression fixes the equation’s shape first (say, a power law or an exponential) then optimizes its parameters. Symbolic regression throws out that constraint entirely. It explores a large space of possible mathematical structures using genetic programming, an evolutionary algorithm that borrows ideas from biology.
Here’s the core idea:
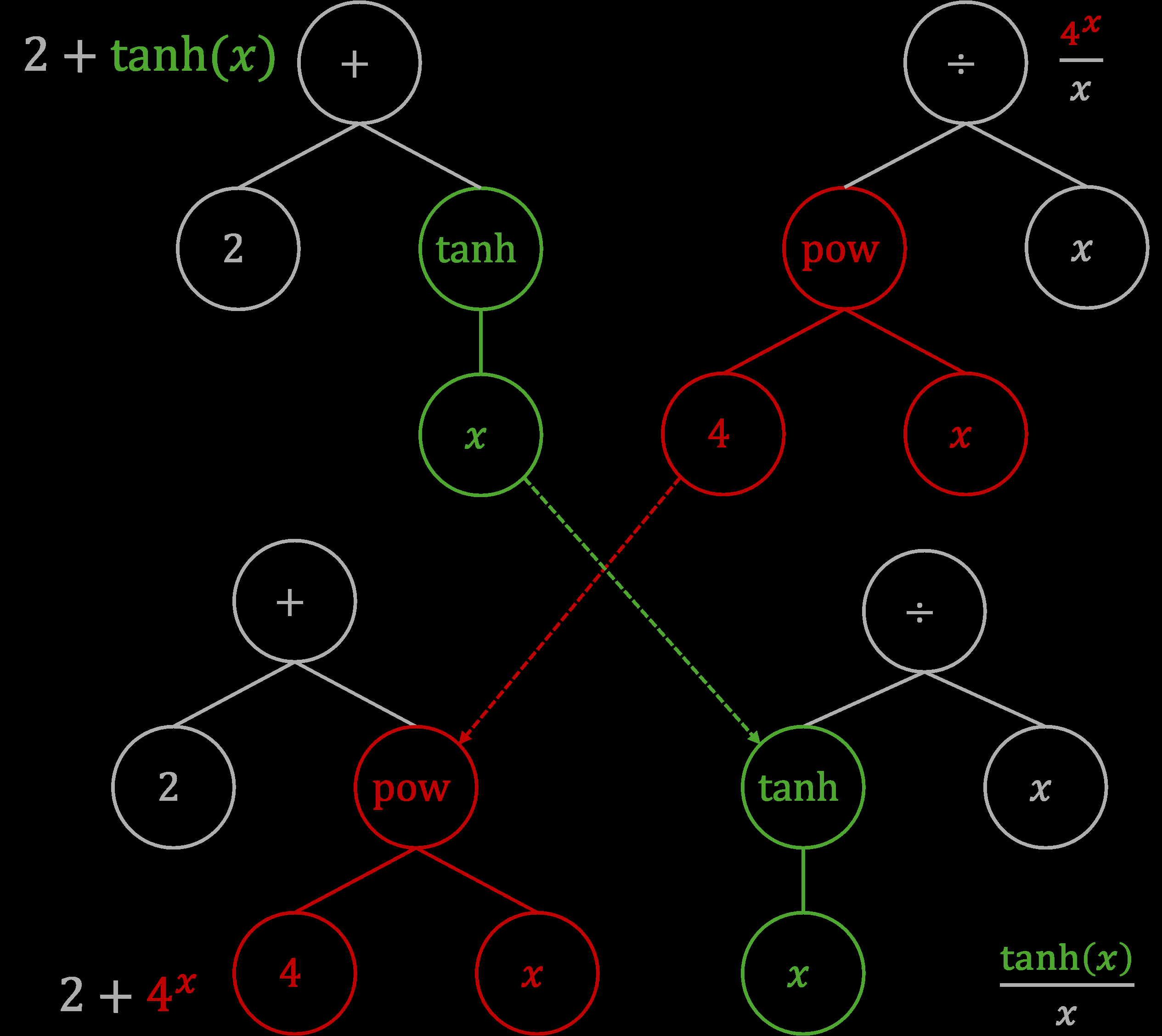
- Functions are represented as expression trees: branching diagrams where each node is a mathematical operator (
+,×,exp,sin, etc.), a variable, or a constant. - The algorithm starts with a population of random expression trees.
- It evolves them through mutation (randomly swapping a node) and crossover (swapping subtrees between two candidates), just like genetic recombination.
- Over many generations, the fittest functions survive and propagate.
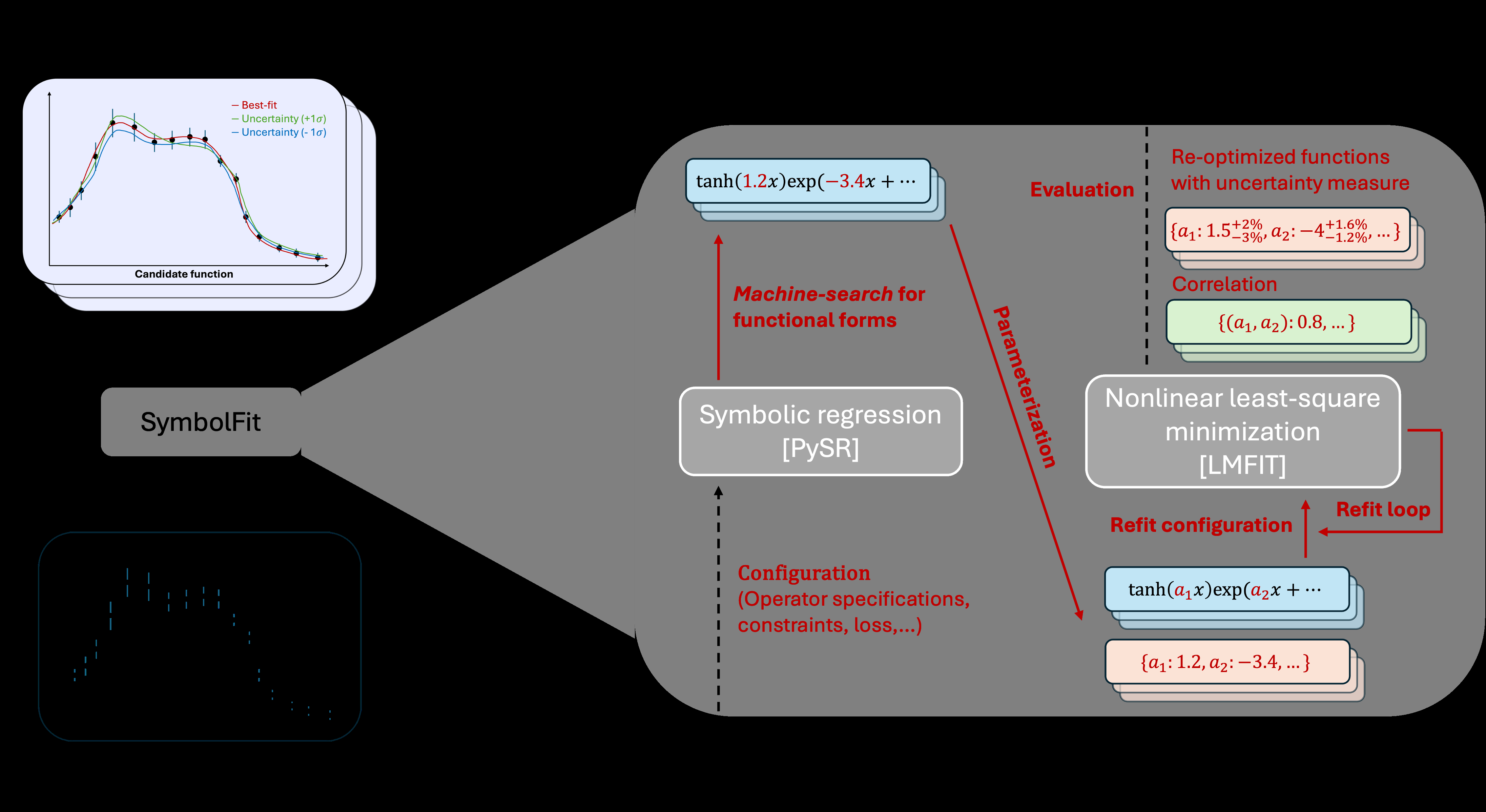
The result is a catalog of candidate functions at varying levels of complexity. SymbolFit then re-optimizes every promising candidate’s free parameters using standard curve-fitting algorithms, computing uncertainty bands at the same time.
That second step matters more than it might sound. Raw symbolic regression outputs best-fit functions but says nothing about how uncertain they are. Without uncertainty estimates, no function can feed into the statistical inference machinery that physicists use to claim a discovery or set a limit on new physics.
SymbolFit builds on PySR, Miles Cranmer’s open-source symbolic regression package. It wraps PySR in a pipeline that handles count data in histogram bins, propagates uncertainties, and outputs results compatible with standard particle physics analysis tools.
Why It Matters
The team validated SymbolFit on five real proton-proton collision datasets from the LHC, covering searches involving dijets, trijets, paired-dijets, diphotons, and dimuons. These are among the highest-energy, highest-statistics datasets from the world’s most powerful particle collider.
A single fit configuration (defining the allowed mathematical building blocks) worked across distributions with substantially different shapes. With traditional methods, each new distribution requires a physicist to start over: rethink the functional form, rerun fits, manually vet results. SymbolFit collapses all of that into one step, varying only the random seed between runs.
For a single dataset, SymbolFit might return dozens of valid candidates. Simple power laws sit alongside exotic combinations of exponentials and polynomials, each with its own uncertainty band. A physicist picks the best-performing ones for downstream analysis, rather than struggling to construct even one good option by hand.
None of this is limited to the LHC. Any field that fits mathematical models to data, from astrophysics and genomics to climate science and economics, faces the same problem: the right functional form is unknown, and searching for it is labor-intensive.
Within particle physics, the stakes are concrete. A wrong background model can generate a fake discovery signal, or bury a real one. By offering many candidate functions with proper uncertainties, SymbolFit gives analysts a more transparent toolkit. It also reduces human bias, since physicists’ prior intuitions inevitably shape which functional forms they try first.
The authors plan to extend SymbolFit to two-dimensional distributions and joint signal-plus-background modeling. The framework is publicly available and open-source.
SymbolFit automates one of experimental physics’ most tedious and error-prone tasks: finding the right equation to describe messy LHC data. It treats the function’s mathematical form itself as something a machine can discover and validate automatically.
IAIFI Research Highlights
SymbolFit puts symbolic regression to work inside LHC data analysis workflows that demand rigorous statistical uncertainty quantification, linking machine learning with experimental high-energy physics practice.
The framework shows that symbolic regression can handle real-world scientific datasets with non-trivial distributions and tight uncertainty requirements, well beyond the toy benchmarks where it is usually tested.
Automating background modeling for resonance searches at the LHC removes a major manual bottleneck from new physics discovery pipelines, potentially speeding up the search for particles and phenomena beyond the Standard Model.
Future extensions include two-dimensional fitting and signal-plus-background joint modeling. The full framework is open-source and the paper is available at [arXiv:2411.09851](https://arxiv.org/abs/2411.09851).
Original Paper Details
SymbolFit: Automatic Parametric Modeling with Symbolic Regression
2411.09851
Ho Fung Tsoi, Dylan Rankin, Cecile Caillol, Miles Cranmer, Sridhara Dasu, Javier Duarte, Philip Harris, Elliot Lipeles, Vladimir Loncar
We introduce SymbolFit, a framework that automates parametric modeling by using symbolic regression to perform a machine-search for functions that fit the data while simultaneously providing uncertainty estimates in a single run. Traditionally, constructing a parametric model to accurately describe binned data has been a manual and iterative process, requiring an adequate functional form to be determined before the fit can be performed. The main challenge arises when the appropriate functional forms cannot be derived from first principles, especially when there is no underlying true closed-form function for the distribution. In this work, we develop a framework that automates and streamlines the process by utilizing symbolic regression, a machine learning technique that explores a vast space of candidate functions without requiring a predefined functional form because the functional form itself is treated as a trainable parameter, making the process far more efficient and effortless than traditional regression methods. We demonstrate the framework in high-energy physics experiments at the CERN Large Hadron Collider (LHC) using five real proton-proton collision datasets from new physics searches, including background modeling in resonance searches for high-mass dijet, trijet, paired-dijet, diphoton, and dimuon events. We show that our framework can flexibly and efficiently generate a wide range of candidate functions that fit a nontrivial distribution well using a simple fit configuration that varies only by random seed, and that the same fit configuration, which defines a vast function space, can also be applied to distributions of different shapes, whereas achieving a comparable result with traditional methods would have required extensive manual effort.