
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models
Authors
Samuel Marks, Can Rager, Eric J. Michaud, Yonatan Belinkov, David Bau, Aaron Mueller
Abstract
We introduce methods for discovering and applying sparse feature circuits. These are causally implicated subnetworks of human-interpretable features for explaining language model behaviors. Circuits identified in prior work consist of polysemantic and difficult-to-interpret units like attention heads or neurons, rendering them unsuitable for many downstream applications. In contrast, sparse feature circuits enable detailed understanding of unanticipated mechanisms. Because they are based on fine-grained units, sparse feature circuits are useful for downstream tasks: We introduce SHIFT, where we improve the generalization of a classifier by ablating features that a human judges to be task-irrelevant. Finally, we demonstrate an entirely unsupervised and scalable interpretability pipeline by discovering thousands of sparse feature circuits for automatically discovered model behaviors.
Concepts
The Big Picture
Imagine trying to understand why a car engine makes a strange noise by looking only at the whole engine block, never at individual pistons, valves, or fuel injectors. That’s what AI interpretability researchers have been doing for years: explaining why a language model behaves a certain way by pointing to broad internal components with names like “attention head 7” or “layer 4.” These components are like engine blocks. Too big, too tangled, and frustratingly vague.
The deeper problem is polysemanticity: individual processing units inside AI language models respond to dozens of unrelated concepts at the same time. A single unit might activate for “banana,” “yellow objects,” and “tropical countries” all at once. Trying to explain a model’s behavior with these blurry units is like describing a symphony by pointing at sections of the orchestra. Technically accurate, but missing everything that matters.
A team from Northeastern University, MIT, and the Technion built a sharper tool. Their sparse feature circuits, published at ICLR 2025, map the interpretable causal wiring behind specific model behaviors. They also built a pipeline that discovers thousands of these circuits automatically.
Key Insight: Swapping out blurry processing units for sharp, meaningful “features” (learned by a specially trained neural network) lets researchers trace exactly which concepts drive a language model’s predictions and surgically edit those pathways.
How It Works
Two technical ideas make this possible.
Sparse autoencoders (SAEs) are neural networks trained to decompose a model’s internal representations into interpretable building blocks. When a language model processes text, each layer produces a stream of numbers encoding what the model “knows” at that point. SAEs re-express those numbers as a combination of features, each tied to a single recognizable concept: “the word ‘doctor’ in a medical context” or “a plural subject in a relative clause.” The researchers trained SAEs for every sublayer of Pythia-70M and used the publicly available Gemma Scope SAEs for Gemma-2-2B.
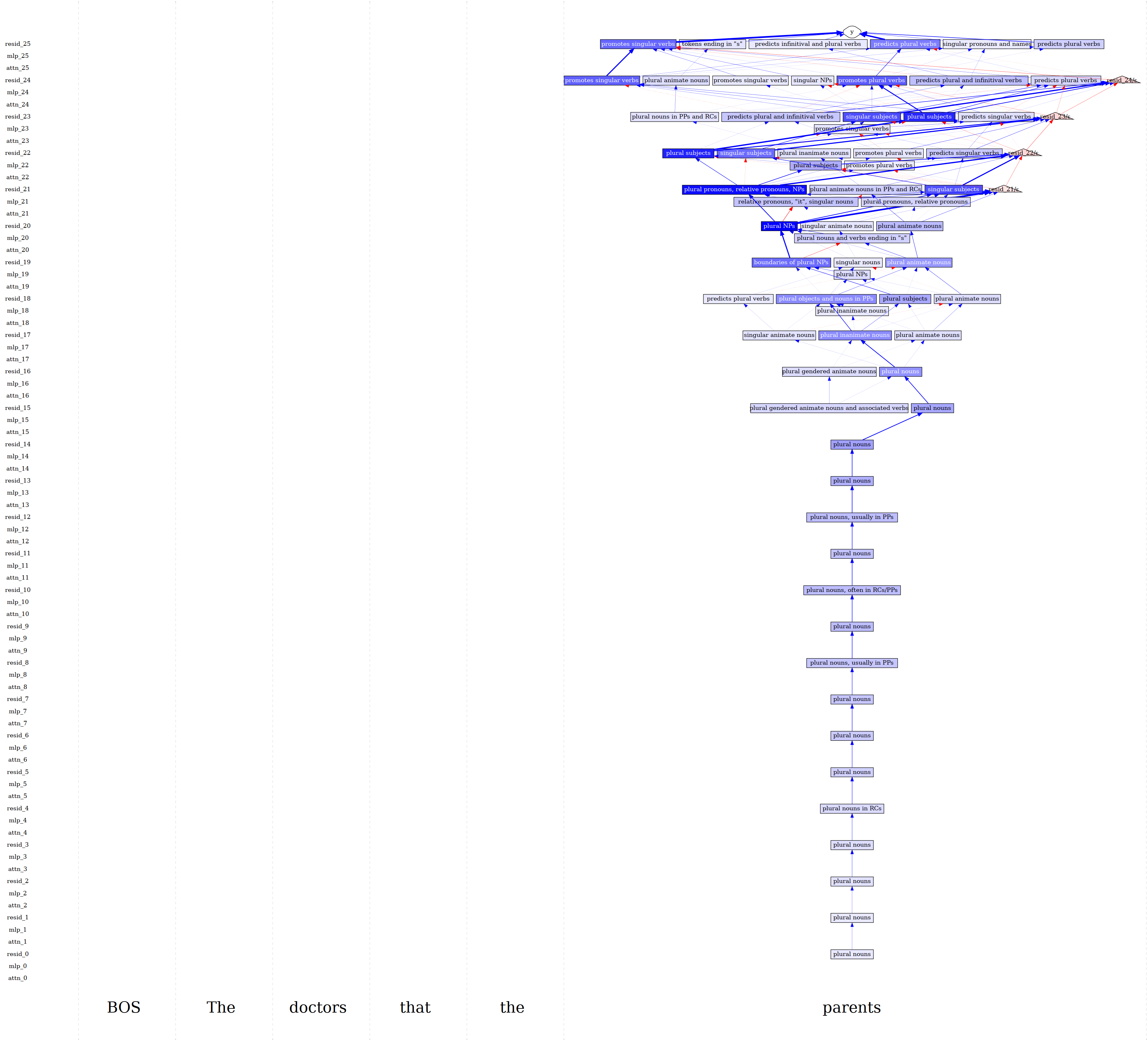
Attribution patching is a fast mathematical technique for estimating how much each feature causally contributes to a specific model output. Given a “clean” input (“The teacher…”) and a “patch” input (“The teachers…”), it estimates how much each feature’s difference shifts the model’s probability of outputting “is” versus “are.” The technique scores thousands of features in parallel, so it scales.
Put them together and the pipeline works like this:
- Define a behavior, for example, subject-verb agreement on sentences with an intervening noun phrase.
- Run SAEs on every sublayer to decompose activations into sparse features.
- Score features using attribution patching to find which ones causally influence that behavior.
- Threshold and connect: keep only the most important features and trace how they communicate across layers, forming a directed graph.
The result is a sparse feature circuit: a graph where nodes are interpretable features and edges represent causal influence.
The SAE error term (the gap between what the SAE captured and what the model actually computed) gets its own node in the circuit. This lets researchers see how much of the model’s behavior the interpretable features actually explain, and how much remains opaque.
Why It Matters
The most immediate application is SHIFT (Sparse Human-Interpretable Feature Trimming), a technique for removing bias from AI classifiers by eliminating irrelevant features. The team tested it on a worst-case scenario: a model trained to predict profession where gender perfectly predicts the correct answer in training data.
Standard bias-removal methods require carefully curated examples where gender and profession are independent. SHIFT doesn’t. A human examines the discovered circuit, identifies features clearly related to gender rather than profession, and removes them. The model’s spurious gender sensitivity drops without any special data.
The team also built a fully unsupervised pipeline that discovers thousands of narrow language model behaviors (“predicting ‘to’ as an infinitive object,” “predicting commas in dates”) using clustering, then automatically computes sparse feature circuits for all of them. Results are publicly browsable at feature-circuits.xyz. That scalability is the real win here: interpretability no longer has to be a hand-crafted, one-behavior-at-a-time endeavor.
Open questions remain. Better SAEs will shrink the unexplained residual. Attribution patching is an approximation, so complex interactions between multiple features could be missed. The method has so far been validated on smaller models, and scaling to frontier systems is still ahead.
Bottom Line: Sparse feature circuits give researchers a causally grounded, interpretable window into language model behavior and a practical tool for editing that behavior without specially curated datasets.
IAIFI Research Highlights
This work brings the precision analysis familiar to physicists into mechanistic interpretability, tracing causal pathways through complex systems with minimal assumptions, much as physicists track particle interactions through a detector.
Sparse feature circuits replace polysemantic, hard-to-interpret units with human-readable features. The unsupervised pipeline can discover thousands of causal explanations for language model behaviors without manual effort.
SHIFT shows that interpretability tools can support targeted edits to model behavior, moving toward AI systems whose internals can be read, understood, and modified with precision.
Future work will focus on improving SAE quality and scaling circuit discovery to larger models. The paper is available at [arXiv:2403.19647](https://arxiv.org/abs/2403.19647), and code is released at [github.com/saprmarks/feature-circuits](https://github.com/saprmarks/feature-circuits).
Original Paper Details
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models
2403.19647
Samuel Marks, Can Rager, Eric J. Michaud, Yonatan Belinkov, David Bau, Aaron Mueller
We introduce methods for discovering and applying sparse feature circuits. These are causally implicated subnetworks of human-interpretable features for explaining language model behaviors. Circuits identified in prior work consist of polysemantic and difficult-to-interpret units like attention heads or neurons, rendering them unsuitable for many downstream applications. In contrast, sparse feature circuits enable detailed understanding of unanticipated mechanisms. Because they are based on fine-grained units, sparse feature circuits are useful for downstream tasks: We introduce SHIFT, where we improve the generalization of a classifier by ablating features that a human judges to be task-irrelevant. Finally, we demonstrate an entirely unsupervised and scalable interpretability pipeline by discovering thousands of sparse feature circuits for automatically discovered model behaviors.