
Remove Symmetries to Control Model Expressivity and Improve Optimization
Authors
Liu Ziyin, Yizhou Xu, Isaac Chuang
Abstract
When symmetry is present in the loss function, the model is likely to be trapped in a low-capacity state that is sometimes known as a "collapse". Being trapped in these low-capacity states can be a major obstacle to training across many scenarios where deep learning technology is applied. We first prove two concrete mechanisms through which symmetries lead to reduced capacities and ignored features during training and inference. We then propose a simple and theoretically justified algorithm, syre, to remove almost all symmetry-induced low-capacity states in neural networks. When this type of entrapment is especially a concern, removing symmetries with the proposed method is shown to correlate well with improved optimization or performance. A remarkable merit of the proposed method is that it is model-agnostic and does not require any knowledge of the symmetry.
Concepts
The Big Picture
Imagine training a world-class athlete who keeps drifting back to the same comfortable corner, never pushing past it. That’s roughly what happens inside a neural network when its training objective has a certain kind of built-in balance. The network finds a stable, mediocre resting spot and stays there. Not because it can’t do better, but because the math actively pulls it back.
This phenomenon, called collapse, is one of the more persistent failure modes in modern deep learning. It shows up in self-supervised learning, language models, physics-informed networks, and almost every other corner of AI research. A model collapses when it stops using significant parts of its capacity: neurons go silent, features get ignored, performance plateaus well below potential. Practitioners have patched around it for years with tricks and heuristics, but nobody had a clean theoretical account of why it happens or a principled fix.
Researchers at MIT and EPFL have now provided both. Liu Ziyin, Yizhou Xu, and Isaac Chuang prove exactly how symmetry causes collapse and propose a one-line algorithm called syre that removes it.
Key Insight: Symmetries in a neural network’s loss function create low-capacity “traps” that gradient descent falls into naturally. Removing those symmetries breaks the traps, and the fix requires no knowledge of what the symmetry actually is.
How It Works
The starting point is a mathematical observation that sounds innocent but isn’t. Many standard training practices (adding weight decay, using certain architectures, designing particular loss functions) introduce reflection symmetries into the loss landscape. These are mirror-image patterns where the loss looks identical from two opposite sides. If you apply a transformation $(I - 2P)\theta$, a reflection through a subspace defined by projection matrix $P$, the loss doesn’t change.
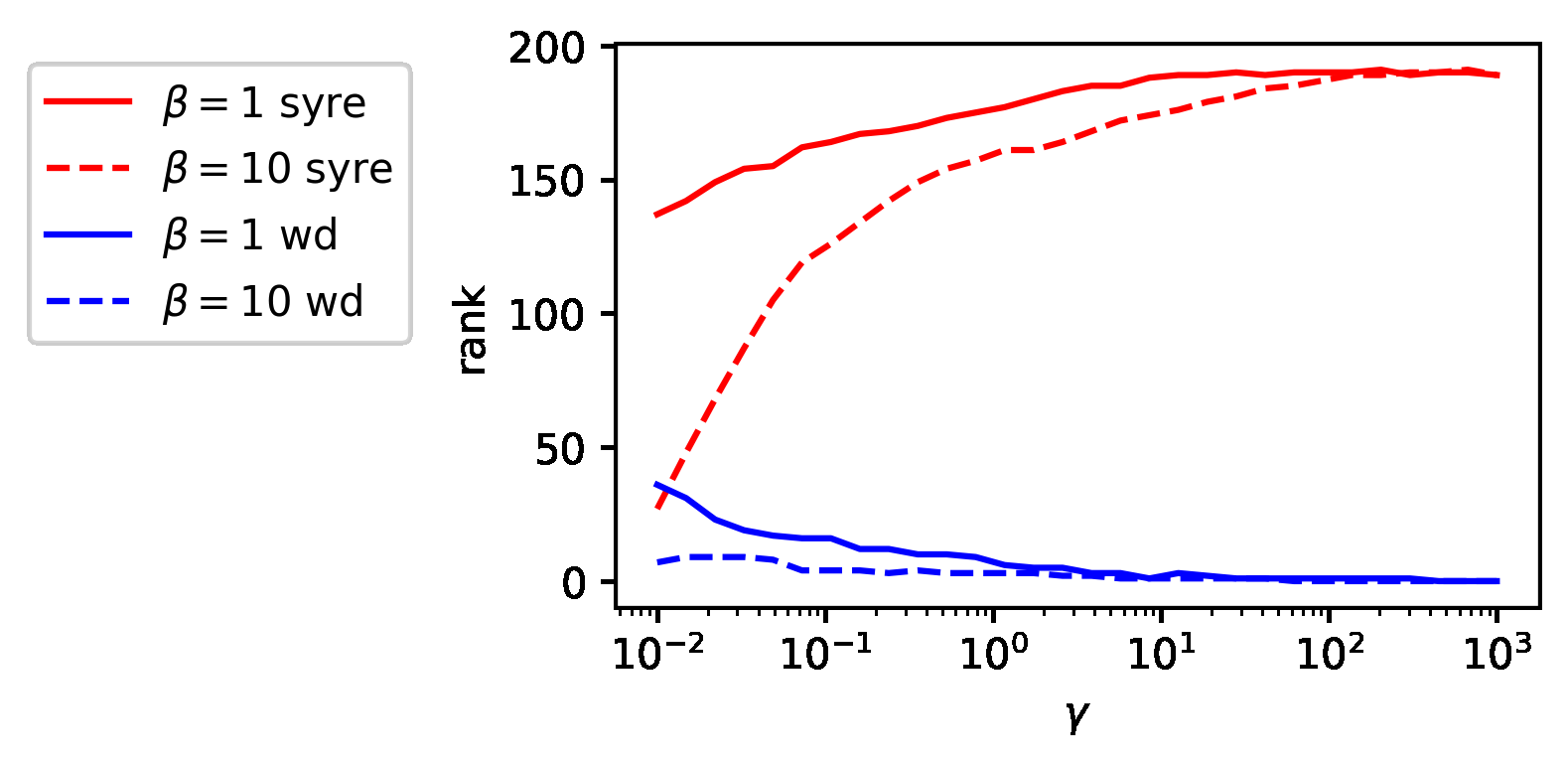
The researchers prove two distinct mechanisms through which these symmetries damage training:
- Capacity reduction via gradient vanishing. Near a symmetric solution, the forces that normally push the network toward higher-capacity solutions become vanishingly small. The model can technically escape, but gradient descent loses traction exactly where it needs it most.
- Weight decay coupling. Standard weight decay (a regularization technique that penalizes large parameter magnitudes) makes things worse. The symmetric version of any parameter configuration always has a smaller magnitude than the original, so weight decay doesn’t just regularize; it actively drags parameters toward symmetric, low-capacity solutions.
The model is both attracted to collapse and unable to escape once it’s close. The symmetric solutions are saddle points (configurations where the terrain slopes favorably in some directions but not others) and they’re particularly sticky ones.
The proposed fix, syre (SYmmetry REmoval), is simple. Rather than identifying and enumerating symmetries, which in nonlinear networks can be hidden and high-dimensional, syre breaks them all at once by adding a small asymmetric perturbation to the loss.
Specifically, it adds a term $\lambda |\theta - \theta_0|^2_D$, where $D$ is a random positive definite matrix. Because $D$ is random and asymmetric, it shatters every reflection symmetry simultaneously. A random $D$ breaks all reflection symmetries with probability one, including ones the practitioner doesn’t know about.
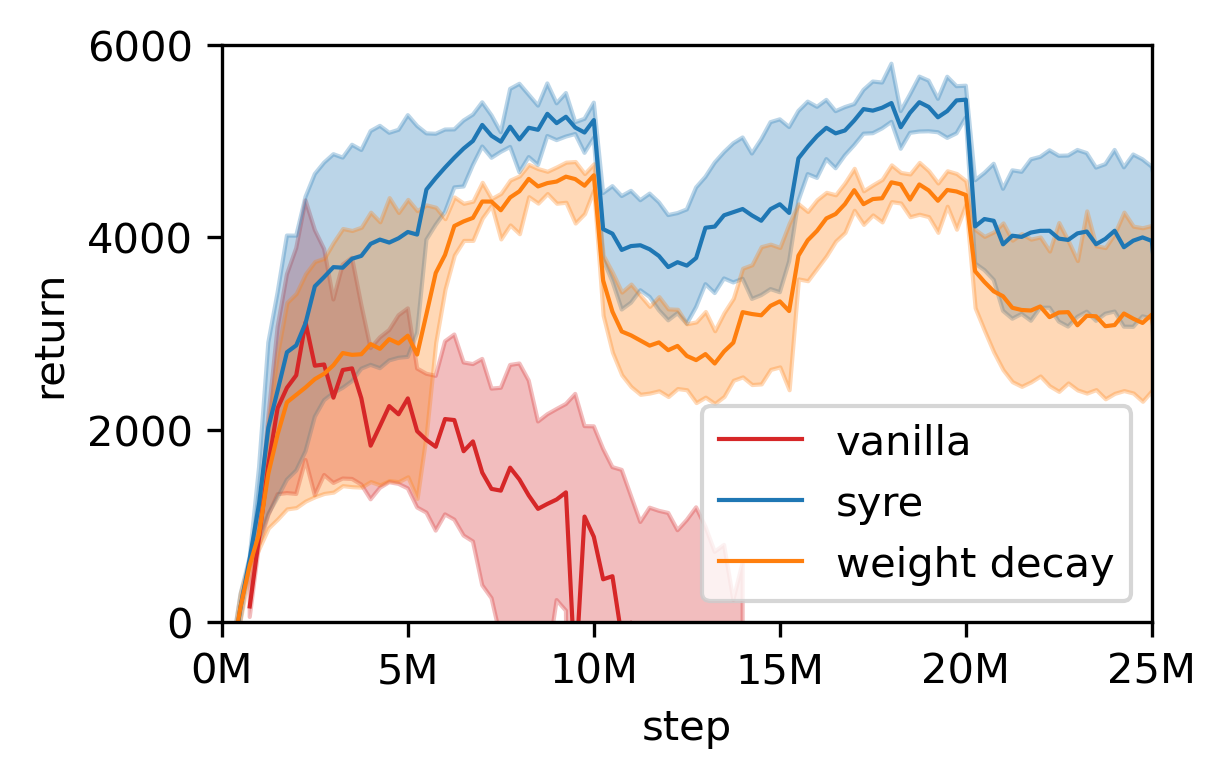
You don’t need to understand your network’s symmetry structure. You don’t need to audit the architecture or the loss function. Add one term, sample a random matrix, and the theoretical guarantees handle the rest.
Why It Matters
Collapse is not a niche problem. It afflicts self-supervised methods, degrades transformers trained with weight decay, and limits physics-informed neural networks that encode symmetries as built-in assumptions. Each of these settings is now, in principle, addressable with a fix that works regardless of model type or the specific symmetries involved.
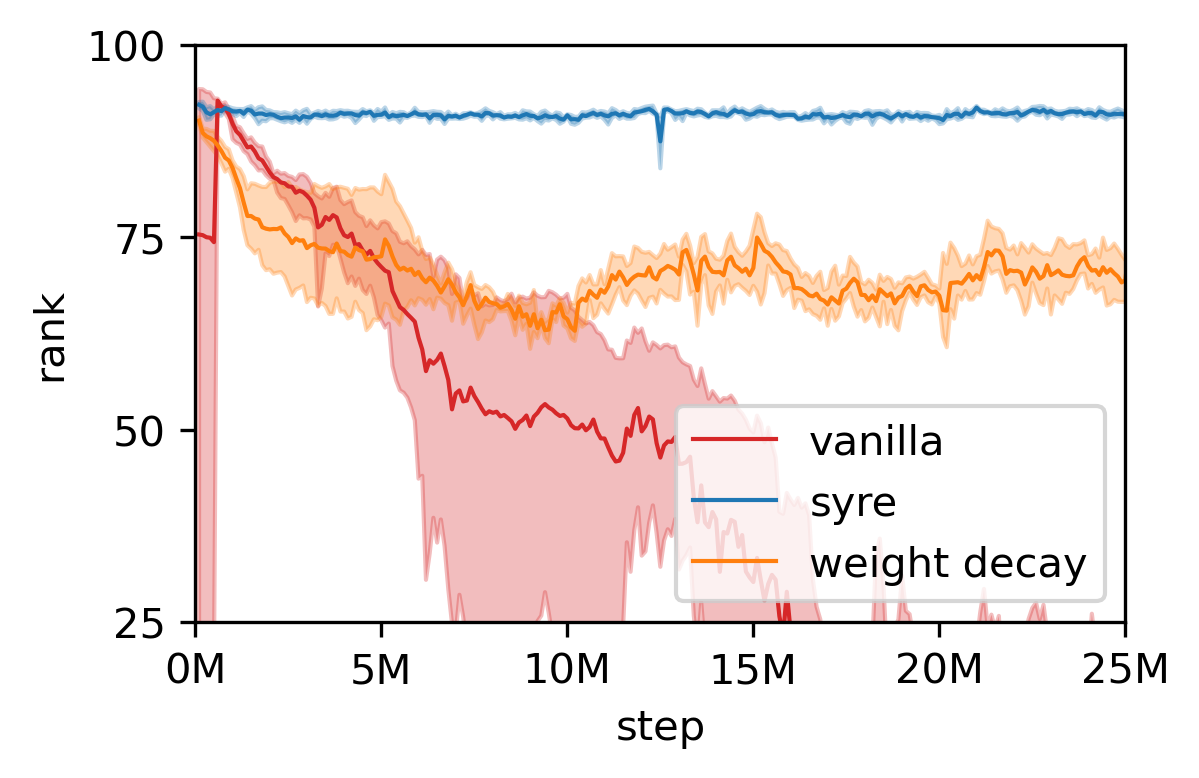
For physics applications, there’s a real tension. Physicists love symmetry and encode it into models deliberately as domain knowledge. But baking too much symmetry into a neural network can inadvertently create the very traps this paper describes. The syre framework offers a way to navigate that: use physics-informed symmetries where they help, but selectively break the ones that threaten training stability.
The geometry of parameter space, like the geometry of physical space, governs what dynamics are even possible. That connection runs deeper than most ML practitioners appreciate.
The open questions are just as interesting. Can syre handle continuous symmetries, not just discrete ones? How does it interact with equivariant architectures? Could the random matrix $D$ be learned alongside the model for even stronger guarantees? This paper doesn’t close the door on symmetry in deep learning. It opens a much more precise one.
Bottom Line: Symmetry-induced collapse is both mechanistically inevitable and mathematically preventable. This is the first clean, principled handle on one of deep learning’s most persistent failure modes, and the fix is a single line of code.
IAIFI Research Highlights
This work applies the physicist's language of symmetry (reflection groups, invariant transformations, projection operators) to diagnose and cure a core failure mode in deep learning. Fundamental physics concepts turn out to have direct, actionable consequences for AI optimization.
The syre algorithm is the first provably correct, model-agnostic method for breaking symmetry-induced collapse in neural networks, with improvements shown across self-supervised learning, language model fine-tuning, and graph neural networks.
By formalizing how symmetry governs the capacity and dynamics of learned representations, this work tightens the connection between symmetry principles in physics and the geometry of neural network loss landscapes.
Future directions include extending the framework to continuous and Lie-group symmetries common in physics-informed networks. The paper by Liu Ziyin, Yizhou Xu, and Isaac Chuang (MIT and EPFL) was published at ICLR 2025. [arXiv:2408.15495](https://arxiv.org/abs/2408.15495)
Original Paper Details
Remove Symmetries to Control Model Expressivity and Improve Optimization
2408.15495
Liu Ziyin, Yizhou Xu, Isaac Chuang
When symmetry is present in the loss function, the model is likely to be trapped in a low-capacity state that is sometimes known as a "collapse". Being trapped in these low-capacity states can be a major obstacle to training across many scenarios where deep learning technology is applied. We first prove two concrete mechanisms through which symmetries lead to reduced capacities and ignored features during training and inference. We then propose a simple and theoretically justified algorithm, syre, to remove almost all symmetry-induced low-capacity states in neural networks. When this type of entrapment is especially a concern, removing symmetries with the proposed method is shown to correlate well with improved optimization or performance. A remarkable merit of the proposed method is that it is model-agnostic and does not require any knowledge of the symmetry.