
Precision Machine Learning
Authors
Eric J. Michaud, Ziming Liu, Max Tegmark
Abstract
We explore unique considerations involved in fitting ML models to data with very high precision, as is often required for science applications. We empirically compare various function approximation methods and study how they scale with increasing parameters and data. We find that neural networks can often outperform classical approximation methods on high-dimensional examples, by auto-discovering and exploiting modular structures therein. However, neural networks trained with common optimizers are less powerful for low-dimensional cases, which motivates us to study the unique properties of neural network loss landscapes and the corresponding optimization challenges that arise in the high precision regime. To address the optimization issue in low dimensions, we develop training tricks which enable us to train neural networks to extremely low loss, close to the limits allowed by numerical precision.
Concepts
The Big Picture
Measuring the width of a human hair with a ruler designed for buildings: that’s roughly the mismatch scientists face when applying machine learning to precision work. Standard ML tools were never built for this. A chatbot doesn’t need next-word probabilities accurate to seven decimal places.
But a physicist trying to rediscover the laws of nature from data needs to get things exactly right.
Precision Machine Learning asks not whether a neural network can learn a mathematical pattern, but whether it can do so with errors smaller than one part in a trillion. At that scale, a small difference in model error can mean the difference between recovering the exact formula and missing it entirely. Standard training methods, tuned for vision and language, fail spectacularly under this level of scrutiny.
Researchers at MIT’s IAIFI set out to understand why precision is hard, compare every major function-fitting method head-to-head, and develop training techniques that push neural networks to the very edge of what computers can numerically represent. Their core finding: neural networks auto-discover hidden modular structure in high-dimensional scientific functions, letting them outperform classical methods, but standard optimizers fall short in low dimensions. Fixing that requires rethinking how we train.
How It Works
The team framed precision ML as a regression problem: given data from symbolic formulas drawn from the Feynman Lectures on Physics, how precisely can different methods recover the underlying function? These equations cover everything from ideal gas laws to relativistic energy. They make perfect test cases because there’s no noise, the mathematical structure is real, and input dimensions range widely.
Total error breaks into four components: optimization error (how far the optimizer lands from its best), sampling luck (statistical fluctuations), generalization gap (train vs. test performance), and architecture error (the best a given model type can ever achieve). In the high-precision regime, architecture error and optimization error dominate. The usual worries about overfitting become secondary.
To compare architectures fairly, the researchers tracked how error shrinks with increasing parameters. The key metric is the scaling exponent α, where loss ∝ N^(−α). Higher α means faster precision gains per parameter added:
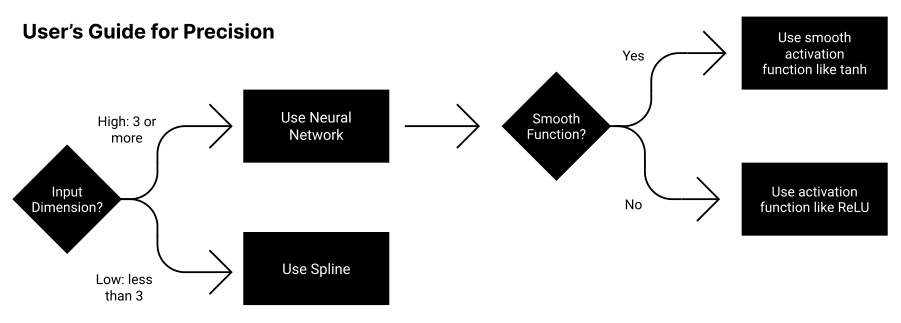
- Piecewise polynomial methods (splines) have theoretically grounded scaling but degrade badly as dimension grows
- Chebyshev polynomials and Fourier series achieve high precision but only for smooth, low-dimensional functions
- Neural networks with standard activations (ReLU, tanh) scale better in higher dimensions by exploiting what the authors call computational modularity: the property that a function is built from composable sub-parts like
sin(x + y²), letting networks learn each piece separately
Modularity is the central insight. Feynman equations are hierarchically structured, with nested additions, multiplications, and simple nonlinearities. Neural networks spontaneously discover these building blocks and represent them efficiently. On 5- or 10-dimensional functions, they outperform classical methods even at equal parameter counts.
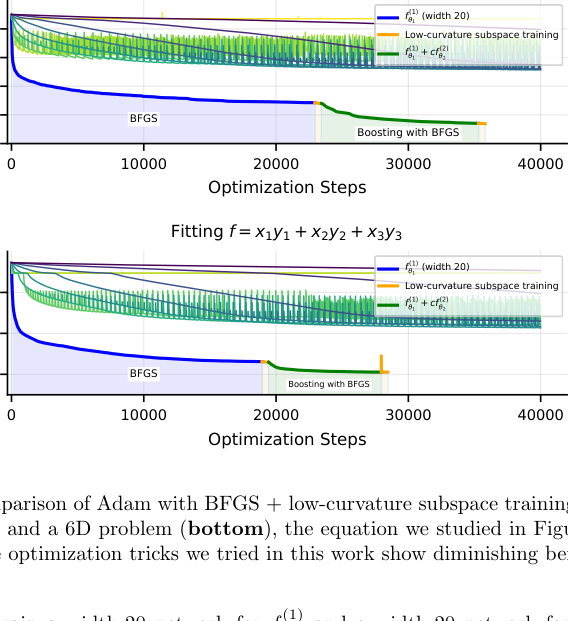
Here’s the catch. In low-dimensional cases, classical methods win. Not because of architecture limits, but because optimization fails. The error surfaces in the high-precision regime are littered with flat regions, saddle points, and narrow valleys that standard gradient descent cannot navigate. The optimizer stalls before reaching the global minimum, even when that minimum theoretically exists.
The fix: aggressive learning rate scheduling (starting large, gradually shrinking), second-order optimization (using curvature information rather than plain gradient descent), and precision-tuned weight initialization. Cycling between optimizers at different training stages, a kind of optimizer annealing, also helped escape local traps.
With these methods, they trained networks to relative RMSE losses of 10^(−14) and below, approaching the 10^(−16) floor imposed by 64-bit floating-point arithmetic. That’s the hard limit of how precisely modern computers store numbers.
Why It Matters
The payoff goes well past benchmarking. Symbolic regression tools like PySR and Eureqa try to discover exact mathematical formulas from data, but they depend on neural network components fitting intermediate representations with high fidelity. When those fits aren’t precise enough, the symbolic discovery pipeline breaks. Precision training is what makes it work.
This work also exposes a blind spot in ML optimization research. Decades of effort have gone into tasks where error of 0.1 is acceptable and 0.01 is excellent. Adam, SGD with momentum, cosine schedules: none of these were designed for the high-precision regime. The bottleneck turns out to be the optimizer, not the architecture. That distinction matters as ML moves deeper into scientific applications.
An open question remains. If neural networks are auto-discovering modular structure in high dimensions, can we read out that structure? Precision training might become a tool for scientific interpretability, one that reveals not just the function but how it’s composed.
When you push neural networks to the limits of floating-point precision, the bottleneck is the optimizer, not the architecture. Fix the optimizer, and you open the door to discovering exact scientific laws from data.
IAIFI Research Highlights
This work connects AI methodology and physics practice directly, using the Feynman Lectures as a benchmark to expose and fix fundamental limitations in how neural networks handle scientific data requiring ultra-high precision.
The paper introduces a training framework, including optimizer annealing and precision-targeted scheduling, that enables neural networks to reach losses within an order of magnitude of the 64-bit floating-point floor, well beyond what standard training achieves.
By showing that neural networks auto-discover modular structure in physics equations, these results make data-driven symbolic regression more viable and bring us closer to recovering exact physical laws from experimental observations.
Future work may extend these techniques to noisy experimental data and multi-output scientific models. The full paper is available at [arXiv:2210.13447](https://arxiv.org/abs/2210.13447).
Original Paper Details
Precision Machine Learning
2210.13447
Eric J. Michaud, Ziming Liu, Max Tegmark
We explore unique considerations involved in fitting ML models to data with very high precision, as is often required for science applications. We empirically compare various function approximation methods and study how they scale with increasing parameters and data. We find that neural networks can often outperform classical approximation methods on high-dimensional examples, by auto-discovering and exploiting modular structures therein. However, neural networks trained with common optimizers are less powerful for low-dimensional cases, which motivates us to study the unique properties of neural network loss landscapes and the corresponding optimization challenges that arise in the high precision regime. To address the optimization issue in low dimensions, we develop training tricks which enable us to train neural networks to extremely low loss, close to the limits allowed by numerical precision.