
PAPERCLIP: Associating Astronomical Observations and Natural Language with Multi-Modal Models
Authors
Siddharth Mishra-Sharma, Yiding Song, Jesse Thaler
Abstract
We present PAPERCLIP (Proposal Abstracts Provide an Effective Representation for Contrastive Language-Image Pre-training), a method which associates astronomical observations imaged by telescopes with natural language using a neural network model. The model is fine-tuned from a pre-trained Contrastive Language-Image Pre-training (CLIP) model using successful observing proposal abstracts and corresponding downstream observations, with the abstracts optionally summarized via guided generation using large language models (LLMs). Using observations from the Hubble Space Telescope (HST) as an example, we show that the fine-tuned model embodies a meaningful joint representation between observations and natural language through tests targeting image retrieval (i.e., finding the most relevant observations using natural language queries) and description retrieval (i.e., querying for astrophysical object classes and use cases most relevant to a given observation). Our study demonstrates the potential for using generalist foundation models rather than task-specific models for interacting with astronomical data by leveraging text as an interface.
Concepts
The Big Picture
Imagine walking into the world’s largest library and asking for “a photo of a barred spiral galaxy with evidence of active star formation.” Now imagine the librarian only speaks a private cataloging language that took decades to develop. That’s roughly the situation astronomers face when trying to search through the billions of images captured by space telescopes.
The images exist. The data is there. But searching it with plain human language? Essentially impossible.
The Hubble Space Telescope has spent over three decades building an archive of observations, from dying stars to colliding galaxies. Each image comes with an associated observing proposal, a document written by scientists explaining what they want to look at and why. These proposals are dense with scientific language, but they are language. And that turns out to be the key.
Researchers at MIT’s Institute for AI and Fundamental Interactions (IAIFI) have built PAPERCLIP, a system that links Hubble images with natural language descriptions using a neural network. The result: you can search astronomical archives the same way you’d search Google Images.
Key Insight: By fine-tuning a general-purpose AI model on pairs of Hubble observations and their scientific proposal abstracts, PAPERCLIP creates a shared “language” between telescope images and human text, enabling free-form natural language search over astronomical data.
How It Works
The foundation of PAPERCLIP is CLIP (Contrastive Language-Image Pre-training), a model originally developed by OpenAI to understand relationships between photographs and captions. CLIP learns by being shown millions of image-text pairs and trained to match them: it pulls matching pairs closer together in a shared mathematical space (an invisible coordinate system where similar concepts cluster nearby) while pushing non-matching pairs apart. A photo of a dog and the word “dog” end up near each other; a photo of a nebula and the word “dog” end up far apart.
The problem is that CLIP was trained on everyday internet images, not on scientific telescope data. Hubble’s observations look nothing like the photographs CLIP learned from. The solution: fine-tuning, where a pre-trained model gets additional training on domain-specific data to adapt it for a new task.

Every successful Hubble observing proposal comes with an abstract, a concise scientific description of what the researchers plan to observe and why. These abstracts are publicly available in the Mikulski Archive for Space Telescopes (MAST), NASA’s repository for Hubble data. By pairing each observation with the abstract of the proposal that generated it, the researchers assembled a natural training set: images linked to text, no hand-labeling required.
There’s a catch. Proposal abstracts are written for expert audiences and focus on scientific justification rather than simple description. To make them more useful for training, the team used guided LLM generation: they ran the abstracts through a large language model to produce concise, structured summaries. These summaries extracted key information like target object type, relevant physical properties, and scientific use case, following a fixed template to keep results consistent.
The training pipeline works as follows:
- Retrieve matched (observation, abstract) pairs from Hubble’s public archive
- Summarize abstracts using guided LLM generation
- Fine-tune CLIP on these pairs using contrastive loss, rewarding the model when it correctly matches images to their corresponding texts
Results: Asking Hubble in Plain English
The team tested PAPERCLIP on two retrieval tasks. In image retrieval, they queried the model with a text description and asked it to find the most relevant Hubble observations from a large candidate pool. In text retrieval, they fed it an image and asked it to identify which astrophysical category (“spiral galaxy,” “planetary nebula,” “globular cluster”) best describes it.
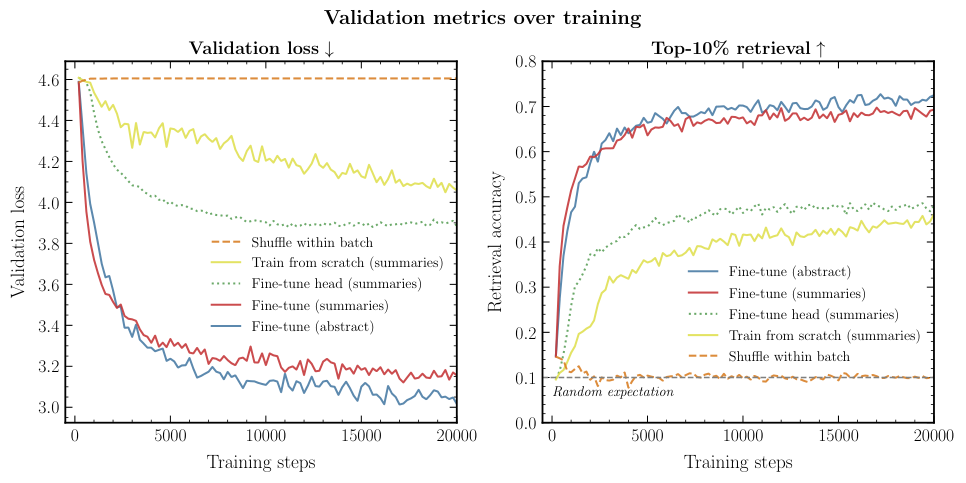
PAPERCLIP substantially outperforms the base CLIP model on both tasks. Fine-tuning actually taught the model something about astronomy, not just generic pattern matching. The version trained on LLM-summarized abstracts also consistently beat the version trained on raw abstracts, confirming that the summarization step was worth the effort.
Ask it to search for “barred spiral galaxy” and PAPERCLIP retrieves images that are recognizably barred spirals. Show it an image of a planetary nebula and it correctly identifies the object class and associated scientific context. The model learned real structure in the data, not just surface-level correlations.
Why It Matters
This goes well beyond Hubble. Astronomy is entering an era of data abundance: the Vera Rubin Observatory will soon generate 20 terabytes of images every night. The Square Kilometre Array will produce data volumes that dwarf anything in existence today. Hand-crafted, task-specific search tools won’t scale.
PAPERCLIP points to a different approach. Take a generalist foundation model, adapt it with a relatively small amount of domain-specific data, and get a useful scientific search tool out the other end. The training signal (proposal abstracts) was always there, sitting in the archive. The trick was recognizing that this existing text could connect human language to scientific imagery without any manual annotation.
The same idea could apply to other telescopes, other wavelengths (radio, X-ray, infrared), and entirely different data types like light curves or spectra. Pairing scientific observations with the documentation that already describes them is not specific to Hubble.
Bottom Line: PAPERCLIP shows that fine-tuning a general-purpose vision-language model on astronomy’s own existing documentation creates a practical search tool. The logical next step: scientists querying any telescope archive with nothing more than natural language.
IAIFI Research Highlights
PAPERCLIP combines foundation model AI with observational astrophysics, repurposing observing proposal abstracts as a training signal to connect telescope images with human language. It's a creative reuse of existing scientific infrastructure.
Guided LLM summarization measurably improves contrastive fine-tuning. The technique generalizes to adapting vision-language models for specialized scientific domains with limited labeled data.
A natural-language interface to Hubble's archive makes decades of astronomical data easier to search and discover, with direct benefits for research across astrophysics.
Future work could extend PAPERCLIP to multi-wavelength surveys, spectral data, and other telescope archives. The paper is available at [arXiv:2403.08851](https://arxiv.org/abs/2403.08851) and the code is open-source at [github.com/smsharma/PAPERCLIP-Hubble](https://github.com/smsharma/PAPERCLIP-Hubble).
Original Paper Details
PAPERCLIP: Associating Astronomical Observations and Natural Language with Multi-Modal Models
[arXiv:2403.08851](https://arxiv.org/abs/2403.08851)
Siddharth Mishra-Sharma, Yiding Song, Jesse Thaler
We present PAPERCLIP (Proposal Abstracts Provide an Effective Representation for Contrastive Language-Image Pre-training), a method which associates astronomical observations imaged by telescopes with natural language using a neural network model. The model is fine-tuned from a pre-trained Contrastive Language-Image Pre-training (CLIP) model using successful observing proposal abstracts and corresponding downstream observations, with the abstracts optionally summarized via guided generation using large language models (LLMs). Using observations from the Hubble Space Telescope (HST) as an example, we show that the fine-tuned model embodies a meaningful joint representation between observations and natural language through tests targeting image retrieval (i.e., finding the most relevant observations using natural language queries) and description retrieval (i.e., querying for astrophysical object classes and use cases most relevant to a given observation). Our study demonstrates the potential for using generalist foundation models rather than task-specific models for interacting with astronomical data by leveraging text as an interface.