
Omnigrok: Grokking Beyond Algorithmic Data
Authors
Ziming Liu, Eric J. Michaud, Max Tegmark
Abstract
Grokking, the unusual phenomenon for algorithmic datasets where generalization happens long after overfitting the training data, has remained elusive. We aim to understand grokking by analyzing the loss landscapes of neural networks, identifying the mismatch between training and test losses as the cause for grokking. We refer to this as the "LU mechanism" because training and test losses (against model weight norm) typically resemble "L" and "U", respectively. This simple mechanism can nicely explain many aspects of grokking: data size dependence, weight decay dependence, the emergence of representations, etc. Guided by the intuitive picture, we are able to induce grokking on tasks involving images, language and molecules. In the reverse direction, we are able to eliminate grokking for algorithmic datasets. We attribute the dramatic nature of grokking for algorithmic datasets to representation learning.
Concepts
The Big Picture
Imagine studying for an exam by cramming thousands of practice problems. You ace every practice test. Perfect score, every time. But then you sit for the real exam and fail completely.
You keep studying, weeks pass, and then one day something clicks. Suddenly you understand the material on a gut level, and your score skyrockets. That’s bizarre, and it’s exactly what researchers caught neural networks doing.
This phenomenon, called grokking, was first observed in 2022 when networks trained on arithmetic tasks memorized training examples almost immediately, then stalled for thousands of training steps before suddenly cracking the pattern and generalizing perfectly. The original discovery raised two questions: Why does this happen, and is it unique to toy arithmetic puzzles?
A team at MIT’s IAIFI set out to answer both. Their explanation comes down to a simple geometric picture of how neural networks navigate the space of possible solutions. Grokking isn’t some quirk of arithmetic datasets. It shows up in image recognition, sentiment analysis, and molecular property prediction too.
Key Insight: Grokking is caused by a mismatch between how training loss and test loss behave as a function of model weight norm. By understanding this “LU mechanism,” researchers can both induce and eliminate grokking across virtually any machine learning task.
How It Works
The key move is to stop watching how a network’s errors change over training steps and instead plot them against how large the model’s weights are.
Do that, and two distinct shapes appear. Training loss (how wrong the model is on examples it has already seen) traces an L-shape: it drops steeply then flattens, meaning many different weight sizes can fit the training data equally well. Test loss (how wrong the model is on new examples) traces a U-shape: there’s a sweet spot where weights must be just the right size for the model to truly generalize.
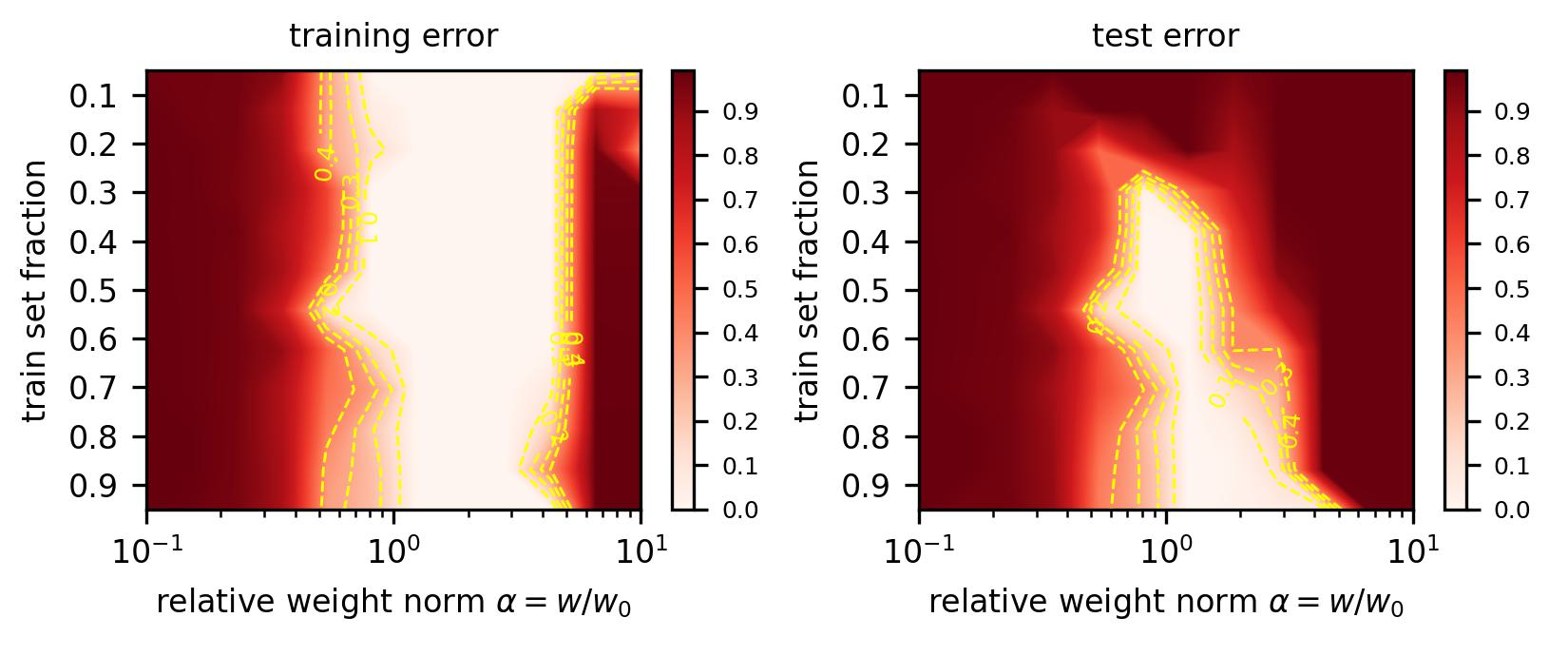
The team calls this the LU mechanism, after those two curves. Here’s how it explains grokking:
- A network initializes with large weights, sitting in the flat bottom of the L-curve.
- It quickly memorizes the training data. Training loss hits near-zero, but the model fails on new examples.
- Regularization, a penalty on large weights, slowly shrinks the weight norm toward the sweet spot.
- When regularization is weak, this drift takes ages, producing the long delay we call grokking.
- When weight decay finally brings the network into range, generalization snaps into place.
There’s a clean quantitative prediction too: if the weight decay coefficient is γ and the initial weight norm is w₀, generalization time scales as ln(w₀/wc)/γ. Halve the weight decay, double the grokking delay.
To test this, Liu, Michaud, and Tegmark used a teacher-student setup where a small “student” network learns to copy the outputs of a fixed, pre-trained “teacher.” This controlled environment let them manipulate every variable and watch exactly how the LU loss landscape governed training dynamics. Large initializations caused grokking. Small initializations caused fast generalization. Tuning regularization moved the network’s trajectory through the loss landscape exactly as predicted.
Why It Matters
With the LU mechanism in hand, the team induced grokking where nobody had seen it before. They deliberately inflated initialization weight norms and triggered grokking on MNIST image classification, IMDb sentiment analysis, and QM9 molecular property prediction. Real datasets, real architectures, full grokking, on demand.
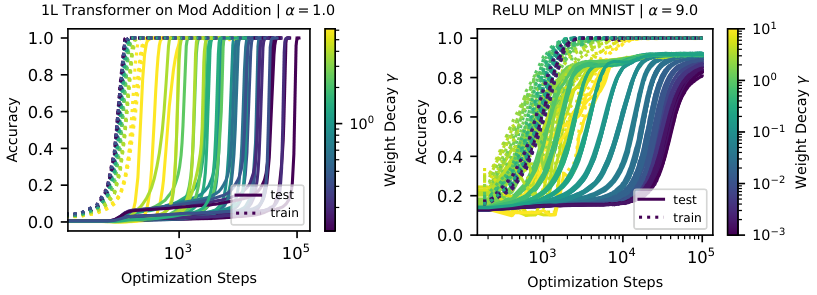
They also ran the movie backward: for algorithmic datasets where grokking is normally dramatic, constraining the weight norm during training almost entirely eliminated the delay. Grokking isn’t inevitable. It’s a consequence of specific geometric conditions that can be engineered away.
The paper also explains why algorithmic tasks produce such extreme grokking compared to image classification. On image tasks, there is essentially one sweet spot, and the network’s internal representations don’t shift much as training progresses. Algorithmic tasks are different: they have two distinct zones, one for memorization-based representations and one for generalizing ones.
The generalizing zone sits at a smaller weight norm. A network starting at standard initialization overshoots it entirely, forcing regularization to work twice as hard. This raises a natural question for future work. Any task where generalizing representations require fundamentally different weight configurations than memorizing ones should be prone to severe grokking. Figuring out which tasks have this property, and how to train around it, is wide open.
Bottom Line: The LU mechanism provides a geometric explanation for grokking that works across domains. By extending it to images, text, and molecules, this work shows grokking is a universal feature of neural network training, not an algorithmic curiosity.
IAIFI Research Highlights
This work uses geometric analysis rooted in physics intuition, examining loss landscapes as surfaces with characteristic shapes, to explain a foundational puzzle in machine learning.
The LU mechanism lets practitioners predict when grokking will occur, induce it experimentally, and eliminate it by constraining weight norms during training.
The sweet-spot framework connects to questions about the geometry of solution spaces in physical systems and how neural networks used in physics simulations find generalizing solutions.
Future work may investigate which real-world tasks have multi-zone loss landscapes and develop training algorithms that efficiently navigate to the generalizing zone; the full paper is available at [arXiv:2210.01117](https://arxiv.org/abs/2210.01117).
Original Paper Details
Omnigrok: Grokking Beyond Algorithmic Data
2210.01117
Ziming Liu, Eric J. Michaud, Max Tegmark
Grokking, the unusual phenomenon for algorithmic datasets where generalization happens long after overfitting the training data, has remained elusive. We aim to understand grokking by analyzing the loss landscapes of neural networks, identifying the mismatch between training and test losses as the cause for grokking. We refer to this as the "LU mechanism" because training and test losses (against model weight norm) typically resemble "L" and "U", respectively. This simple mechanism can nicely explain many aspects of grokking: data size dependence, weight decay dependence, the emergence of representations, etc. Guided by the intuitive picture, we are able to induce grokking on tasks involving images, language and molecules. In the reverse direction, we are able to eliminate grokking for algorithmic datasets. We attribute the dramatic nature of grokking for algorithmic datasets to representation learning.