
Not All Language Model Features Are One-Dimensionally Linear
Authors
Joshua Engels, Eric J. Michaud, Isaac Liao, Wes Gurnee, Max Tegmark
Abstract
Recent work has proposed that language models perform computation by manipulating one-dimensional representations of concepts ("features") in activation space. In contrast, we explore whether some language model representations may be inherently multi-dimensional. We begin by developing a rigorous definition of irreducible multi-dimensional features based on whether they can be decomposed into either independent or non-co-occurring lower-dimensional features. Motivated by these definitions, we design a scalable method that uses sparse autoencoders to automatically find multi-dimensional features in GPT-2 and Mistral 7B. These auto-discovered features include strikingly interpretable examples, e.g. circular features representing days of the week and months of the year. We identify tasks where these exact circles are used to solve computational problems involving modular arithmetic in days of the week and months of the year. Next, we provide evidence that these circular features are indeed the fundamental unit of computation in these tasks with intervention experiments on Mistral 7B and Llama 3 8B, and we examine the continuity of the days of the week feature in Mistral 7B. Overall, our work argues that understanding multi-dimensional features is necessary to mechanistically decompose some model behaviors.
Concepts
The Big Picture
Imagine trying to understand a foreign language by assuming every word is a single note, a simple “yes” or “no” signal. That’s roughly what researchers have been doing with AI language models. For years, a leading theory held that these systems think by activating clean, isolated signals: one for “royalty,” another for “France,” another for “past tense.” A neat theory, and possibly an incomplete one.
A team from MIT and the Institute for AI and Fundamental Interactions (IAIFI) has shown that some of what happens inside large language models is more complex than that. When a language model processes Monday, Tuesday, Wednesday, it doesn’t just toggle a single switch. It traces a circle.
The paper, published at ICLR 2025, challenges the dominant linear representation hypothesis: the idea that every concept a language model handles corresponds to a single, isolated signal. The researchers found that certain concepts require inherently multi-dimensional structure (think a shape, not a point) and built tools to find these structures automatically.
Key Insight: Language models like GPT-2 and Mistral 7B internally represent cyclical concepts, such as days of the week and months of the year, as circles in their activation space. These circles are the actual computational machinery the models use to reason about time.
How It Works
The central question sounds simple: when can a representation not be broken down into simpler pieces? The team formalized this with a rigorous definition of irreducible multi-dimensional features, representations that require multiple dimensions and can’t be split into either independent simpler parts or parts that never co-occur.
To find these features automatically, the researchers used sparse autoencoders (SAEs), a technique that decomposes a model’s internal signals into a large dictionary of component signals, like decomposing a chord into individual notes. SAEs have become a core tool of mechanistic interpretability, the field trying to reverse-engineer how neural networks actually work. Rather than treating each dictionary element as standalone, the team looked for clusters of elements that light up together in structured patterns.
The pipeline:
- Train sparse autoencoders on the internal activations of GPT-2-small and Mistral 7B.
- Compute how often each pair of SAE features lights up together across a large text corpus.
- Cluster the co-activation graph to find tight groups of features.
- Apply a statistical test, comparing actual cluster variance against what independent features would produce, to flag irreducible multi-dimensional candidates.
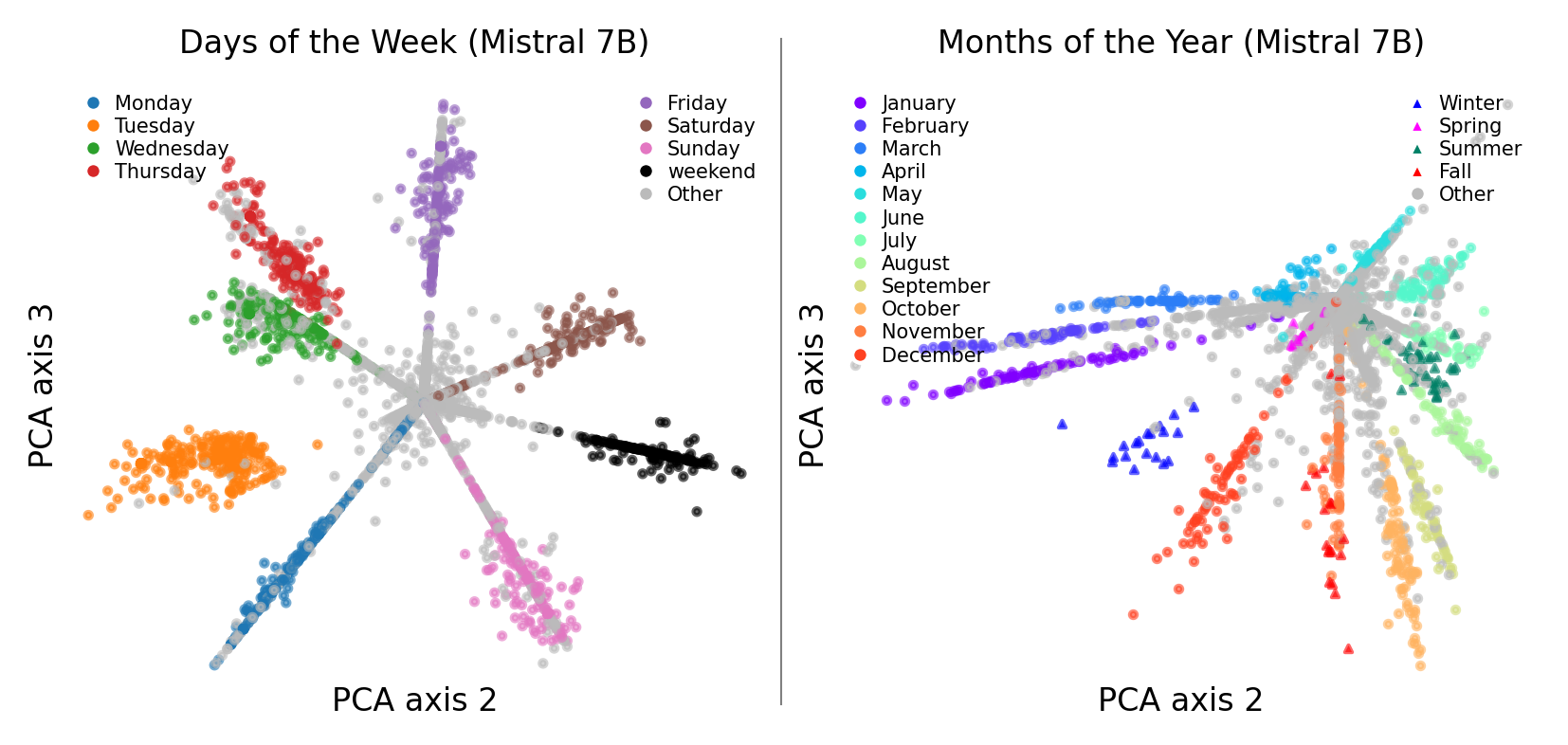
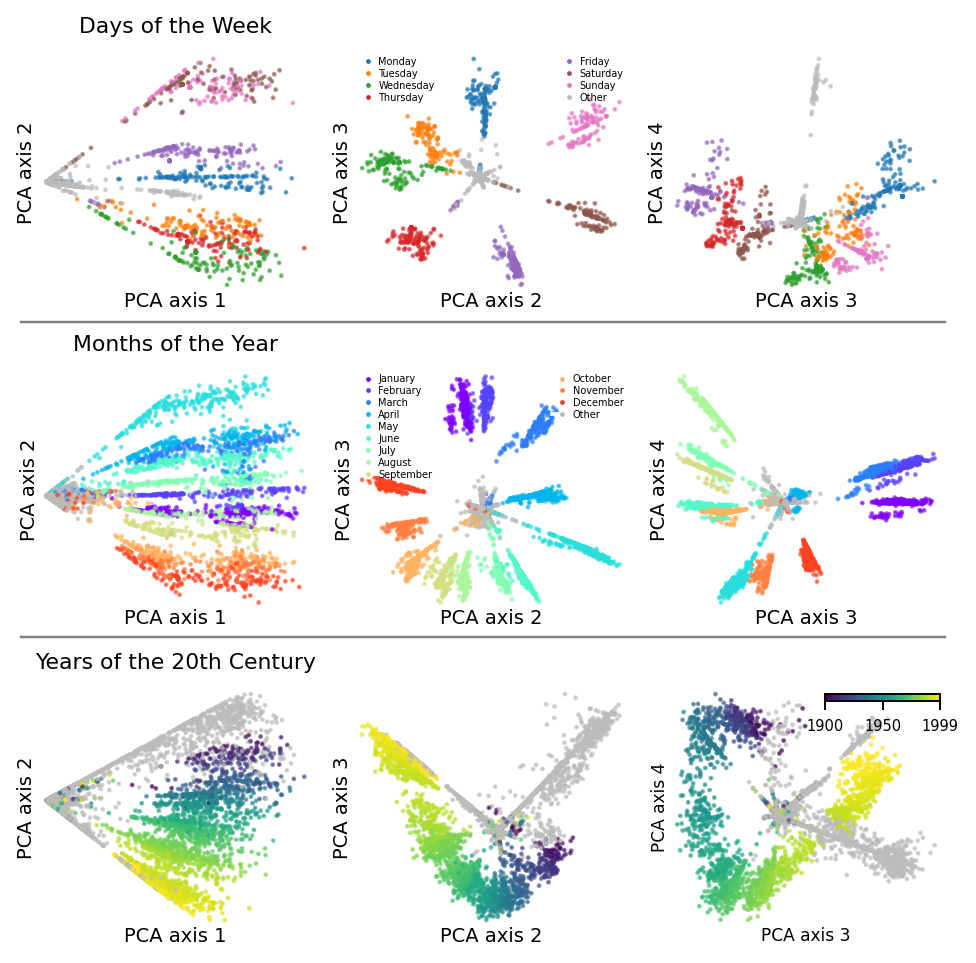
Visualizing the discovered clusters with PCA (a standard technique for collapsing complex data to its most important dimensions), the days of the week formed a perfect circle in a two-dimensional subspace of layer 7 in GPT-2-small. Monday through Sunday, spiraling in order. Months of the year made the same shape. Even years of the 20th century traced a circular arc.
This wasn’t a visualization artifact. The geometry was genuinely present in the model’s internals.
A pretty picture is one thing, though. The harder question is whether these circles matter for computation. The researchers designed careful activation patching experiments, surgically replacing the circular representation mid-computation, to test whether the model actually depends on them.
Ask a language model “If today is Thursday, what day is it in four days?” and it must compute (4 + 4) mod 7 = 1, which maps to Monday. Modular arithmetic, the kind that wraps around, is geometrically natural on a circle. When the team patched in the circular representation for a different starting day in Mistral 7B and Llama 3 8B, the model’s answer changed in exactly the way the circle’s geometry predicts. The circle isn’t decorative. It’s the variable the model passes through its circuits to solve the problem.
Erasing the full circular feature degraded performance far more than erasing any single one-dimensional component of it. The whole really is more than the sum of its parts. When text referred to “early Monday” versus “late Monday,” the model’s representation shifted continuously around the circle, treating time as a smooth analog quantity rather than discrete buckets. The model seems to have learned something like a continuous clock.
Why It Matters
If multi-dimensional features control some model behaviors, then tools built around single isolated signals will systematically miss them. Sparse autoencoders trained to find one-dimensional building blocks will, at best, carve a circle into disconnected fragments that look meaningless in isolation. There’s a real blind spot in the field’s current toolkit.
This connects to a hard problem in AI safety and alignment: can we fully understand what a model is doing? If the true computational units include geometric objects like circles, tori (donut shapes), or stranger curved surfaces, then interpretability needs a richer mathematical vocabulary than a list of labeled signals. What other shapes might be hiding in there? Helices, grids, fractals? Nobody knows yet whether complex reasoning tasks rely on multi-dimensional internal representations that current tools can’t capture.
Bottom Line: Language models encode cyclical concepts like days and months as literal geometric circles in their activation space. These circles are the variables driving modular arithmetic computations, not a byproduct of training. Understanding what’s really going on inside AI may require moving past the assumption that every feature is a single line.
IAIFI Research Highlights
This work brings ideas from physics and geometry (the topology of circles, continuous symmetry) into mechanistic interpretability. AI models spontaneously learn representations that physicists would recognize as compact manifolds.
The paper challenges the dominant linear representation hypothesis and introduces scalable tools for discovering irreducible multi-dimensional features in large language models. It exposes a class of internal structure that prior interpretability methods missed.
Neural networks representing periodic quantities as circles mirrors how physicists encode cyclic symmetries in physical theories. There may be deep structural parallels between what AI models learn and the mathematical objects that describe nature.
Future work will need to catalog the full zoo of possible feature geometries, from circles to tori to helices, to build mechanistic accounts of complex model behaviors; the paper is available at [arXiv:2405.14860](https://arxiv.org/abs/2405.14860).
Original Paper Details
Not All Language Model Features Are One-Dimensionally Linear
2405.14860
Joshua Engels, Eric J. Michaud, Isaac Liao, Wes Gurnee, Max Tegmark
Recent work has proposed that language models perform computation by manipulating one-dimensional representations of concepts ("features") in activation space. In contrast, we explore whether some language model representations may be inherently multi-dimensional. We begin by developing a rigorous definition of irreducible multi-dimensional features based on whether they can be decomposed into either independent or non-co-occurring lower-dimensional features. Motivated by these definitions, we design a scalable method that uses sparse autoencoders to automatically find multi-dimensional features in GPT-2 and Mistral 7B. These auto-discovered features include strikingly interpretable examples, e.g. circular features representing days of the week and months of the year. We identify tasks where these exact circles are used to solve computational problems involving modular arithmetic in days of the week and months of the year. Next, we provide evidence that these circular features are indeed the fundamental unit of computation in these tasks with intervention experiments on Mistral 7B and Llama 3 8B, and we examine the continuity of the days of the week feature in Mistral 7B. Overall, our work argues that understanding multi-dimensional features is necessary to mechanistically decompose some model behaviors.