
Machine Learning on Heterogeneous, Edge, and Quantum Hardware for Particle Physics (ML-HEQUPP)
Authors
Julia Gonski, Jenni Ott, Shiva Abbaszadeh, Sagar Addepalli, Matteo Cremonesi, Jennet Dickinson, Giuseppe Di Guglielmo, Erdem Yigit Ertorer, Lindsey Gray, Ryan Herbst, Christian Herwig, Tae Min Hong, Benedikt Maier, Maryam Bayat Makou, David Miller, Mark S. Neubauer, Cristián Peña, Dylan Rankin, Seon-Hee, Seo, Giordon Stark, Alexander Tapper, Audrey Corbeil Therrien, Ioannis Xiotidis, Keisuke Yoshihara, G Abarajithan, Sagar Addepalli, Nural Akchurin, Carlos Argüelles, Saptaparna Bhattacharya, Lorenzo Borella, Christian Boutan, Tom Braine, James Brau, Martin Breidenbach, Antonio Chahine, Talal Ahmed Chowdhury, Yuan-Tang Chou, Seokju Chung, Alberto Coppi, Mariarosaria D'Alfonso, Abhilasha Dave, Chance Desmet, Angela Di Fulvio, Karri DiPetrillo, Javier Duarte, Auralee Edelen, Jan Eysermans, Yongbin Feng, Emmett Forrestel, Dolores Garcia, Loredana Gastaldo, Julián García Pardiñas, Lino Gerlach, Loukas Gouskos, Katya Govorkova, Carl Grace, Christopher Grant, Philip Harris, Ciaran Hasnip, Timon Heim, Abraham Holtermann, Tae Min Hong, Gian Michele Innocenti, Koji Ishidoshiro, Miaochen Jin, Jyothisraj Johnson, Stephen Jones, Andreas Jung, Georgia Karagiorgi, Ryan Kastner, Nicholas Kamp, Doojin Kim, Kyoungchul Kong, Katie Kudela, Jelena Lalic, Bo-Cheng Lai, Yun-Tsung Lai, Tommy Lam, Jeffrey Lazar, Aobo Li, Zepeng Li, Haoyun Liu, Vladimir Lončar, Luca Macchiarulo, Christopher Madrid, Benedikt Maier, Zhenghua Ma, Prashansa Mukim, Mark S. Neubauer, Victoria Nguyen, Sungbin Oh, Isobel Ojalvo, Hideyoshi Ozaki, Simone Pagan Griso, Myeonghun Park, Christoph Paus, Santosh Parajuli, Benjamin Parpillon, Sara Pozzi, Ema Puljak, Benjamin Ramhorst, Amy Roberts, Larry Ruckman, Kate Scholberg, Sebastian Schmitt, Noah Singer, Eluned Anne Smith, Alexandre Sousa, Michael Spannowsky, Sioni Summers, Yanwen Sun, Daniel Tapia Takaki, Antonino Tumeo, Caterina Vernieri, Belina von Krosigk, Yash Vora, Linyan Wan, Michael H. L. S. Wang, Amanda Weinstein, Andy White, Simon Williams, Felix Yu
Abstract
The next generation of particle physics experiments will face a new era of challenges in data acquisition, due to unprecedented data rates and volumes along with extreme environments and operational constraints. Harnessing this data for scientific discovery demands real-time inference and decision-making, intelligent data reduction, and efficient processing architectures beyond current capabilities. Crucial to the success of this experimental paradigm are several emerging technologies, such as artificial intelligence and machine learning (AI/ML), silicon microelectronics, and the advent of quantum algorithms and processing. Their intersection includes areas of research such as low-power and low-latency devices for edge computing, heterogeneous accelerator systems, reconfigurable hardware, novel codesign and synthesis strategies, readout for cryogenic or high-radiation environments, and analog computing. This white paper presents a community-driven vision to identify and prioritize research and development opportunities in hardware-based ML systems and corresponding physics applications, contributing towards a successful transition to the new data frontier of fundamental science.
Concepts
The Big Picture
Imagine trying to drink from a fire hose. Not a garden-variety fire hose, but one that delivers more water per second than Niagara Falls. That’s roughly the data challenge facing the next generation of particle physics experiments. When the Large Hadron Collider’s High-Luminosity upgrade (a planned overhaul that will dramatically increase collision rates) goes live, detectors will register particle collisions at rates exceeding 40 million per second. The resulting data volumes would overwhelm even the most ambitious computing centers on Earth if everything were recorded. Something has to give, and that something has to be smarter.
A broad coalition of over 100 physicists and engineers from CERN, MIT, Fermilab, SLAC, Harvard, and dozens of other institutions has come together to chart a path forward. Their answer isn’t just “more servers.” It’s a fundamental rethink of where and how computation happens, pushing AI-powered decision-making into the detector hardware itself, measured in microseconds and milliwatts rather than minutes and megawatts.
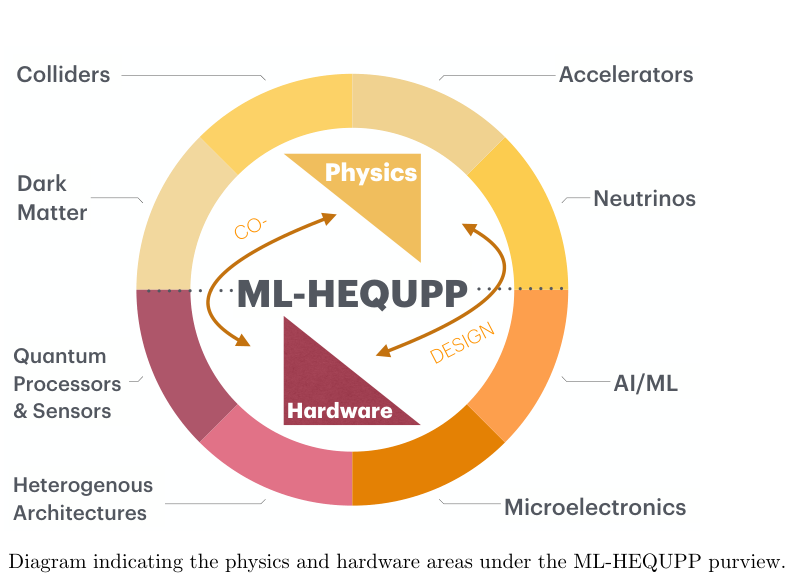
This white paper, the ML-HEQUPP report, presents a community-driven roadmap for harnessing machine learning on specialized chips, programmable hardware, and quantum processors. It lays out both the technological building blocks and the physics goals they’re meant to serve.
Key Insight: The future of particle physics discovery depends not just on better detectors, but on embedding intelligent, real-time AI directly into the hardware that reads those detectors, before most data ever reaches a traditional computer.
How It Works
The challenge breaks into two interlocking problems: the hardware that runs the algorithms, and the algorithms themselves. The white paper covers both, organized around four major hardware paradigms.
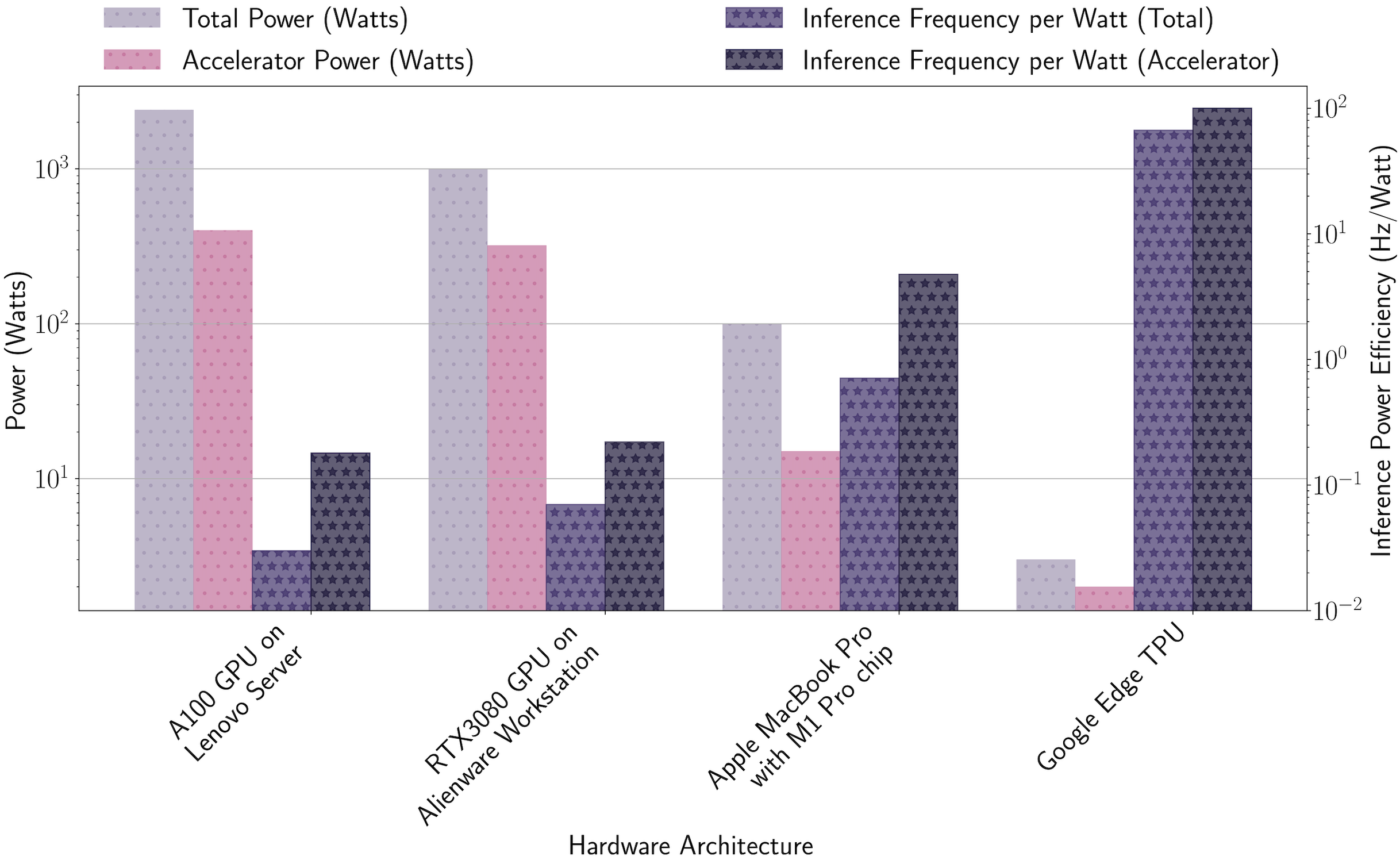
Application-Specific Integrated Circuits (ASICs) are custom silicon chips built for one job and optimized to do it with extreme efficiency. Unlike general-purpose processors, an ASIC baked into a detector’s front-end electronics (the circuits that first receive raw signals from the detector) can process those signals in nanoseconds while consuming just milliwatts of power. Detectors have thousands of signal-reading channels operating in high-radiation environments where you can’t simply swap in a new chip every year.
Projects like AIML65P1 co-design neural networks and silicon together, so the network architecture literally shapes the chip’s transistor layout. The result: maximum speed from minimal power.
Field-Programmable Gate Arrays (FPGAs) occupy the middle ground. These reconfigurable chips can be reprogrammed after deployment. The hls4ml project, one of the field’s flagship open-source tools, lets physicists describe a neural network in a high-level language and automatically translate it into FPGA firmware (low-level instructions baked directly into the chip). A graph neural network that would take seconds on a CPU can run in under a microsecond on an FPGA, enabling real-time trigger decisions: the split-second choices about which collision events are worth keeping.
Complementing hls4ml are CGRA4ML, which targets a different class of reconfigurable chip, and the SLAC Neural Network Language (SNL), a software layer that lets the same model run on different hardware types without rewriting from scratch.
- Latency targets: Many trigger applications require inference in 25–500 nanoseconds, comparable to the time between LHC bunch crossings
- Quantization: Models are compressed to 4- or 8-bit integers without sacrificing physics performance, shrinking both resource use and power
- Decision forests: Gradient-boosted tree ensembles can be mapped to lookup tables on FPGAs, achieving sub-100-nanosecond inference
Quantum hardware represents the most speculative but potentially transformative frontier. These are computers that exploit quantum-mechanical effects rather than conventional binary logic. The paper surveys superconducting qubits, trapped ions, and photonic systems, then maps out quantum algorithm families relevant to physics: quantum support vector machines (pattern classifiers), variational quantum eigensolvers (algorithms for finding lowest-energy states), and quantum-enhanced anomaly detection. Quantum sensing and networking could also enable new coordinated readout schemes across distributed detectors, with fundamentally different noise properties than classical systems.
Analog computing takes the most radical departure. Rather than converting every detector signal into digital numbers before processing, analog brain-inspired circuits perform computations directly in the electrical domain, working with continuous flows of charge and voltage rather than ones and zeros. This approach can achieve energy efficiencies orders of magnitude beyond digital implementations. That matters where power budgets are measured in watts per square meter of silicon.
Why It Matters
The High-Luminosity LHC will collide protons roughly five times more frequently than today. Without smarter processing built directly into the detector hardware, the experiment will be forced to discard the vast majority of events, including potentially the rare ones harboring new physics. Similar pressures apply across the experimental frontier: DUNE’s liquid argon neutrino detectors, dark matter experiments like SuperCDMS operating at millikelvin temperatures, and gravitational wave observatories all face versions of the same problem.
The white paper’s real significance is its scope. This isn’t a single group solving one bottleneck. It represents a genuine community convergence: a shared vocabulary and priority list for R&D over the next decade. The recommendations span training infrastructure, model compression workflows, analysis facility design, and co-design methodologies that treat hardware and algorithm as a single unified system. Including quantum computing as a future direction signals planning on timescales where quantum advantage (the point at which quantum computers meaningfully outperform classical ones on specific tasks) may become practically relevant.
Open questions remain abundant. How do you validate a neural network running inside a radiation-soaked ASIC that you can’t easily reprogram? How much do quantum error rates need to improve before quantum ML offers genuine advantage over conventional real-time computing at the detector? How do you build software ecosystems that let a physicist train a model on a GPU cluster and deploy it to firmware without specialized hardware expertise?
These are engineering and scientific questions at the same time, and this roadmap frames them as tractable.
Bottom Line: ML-HEQUPP charts a decade-long vision for embedding real-time AI into the physical fabric of particle physics detectors. If the next generation of experiments is going to convert its fire-hose data streams into discoveries, this is how.
IAIFI Research Highlights
This white paper connects machine learning (including graph neural networks, quantization, and quantum algorithms) with the concrete hardware constraints of particle physics detectors, showing how AI architecture and silicon design must co-evolve.
The work pushes ultra-low-latency, ultra-low-power inference into new territory, developing tools like `hls4ml` that translate trained neural networks into hardware firmware operating at nanosecond timescales, a regime far beyond conventional AI deployment.
By enabling smarter real-time data reduction directly at the detector, these technologies will determine which rare collision events from the High-Luminosity LHC, future neutrino experiments, and dark matter searches are preserved for scientific analysis.
The roadmap targets co-design of analog, digital, and quantum hardware with physics algorithms as the central R&D priority for the coming decade; the full white paper is available as [arXiv:2602.22248](https://arxiv.org/abs/2602.22248).