
Lorentz-Equivariant Geometric Algebra Transformers for High-Energy Physics
Authors
Jonas Spinner, Victor Bresó, Pim de Haan, Tilman Plehn, Jesse Thaler, Johann Brehmer
Abstract
Extracting scientific understanding from particle-physics experiments requires solving diverse learning problems with high precision and good data efficiency. We propose the Lorentz Geometric Algebra Transformer (L-GATr), a new multi-purpose architecture for high-energy physics. L-GATr represents high-energy data in a geometric algebra over four-dimensional space-time and is equivariant under Lorentz transformations, the symmetry group of relativistic kinematics. At the same time, the architecture is a Transformer, which makes it versatile and scalable to large systems. L-GATr is first demonstrated on regression and classification tasks from particle physics. We then construct the first Lorentz-equivariant generative model: a continuous normalizing flow based on an L-GATr network, trained with Riemannian flow matching. Across our experiments, L-GATr is on par with or outperforms strong domain-specific baselines.
Concepts
The Big Picture
Imagine teaching a student physics by making them memorize every possible outcome of every possible experiment, without ever mentioning symmetry. They’d eventually learn that dropping a ball in Paris gives the same result as dropping one in Tokyo, but only after seeing both. Now imagine teaching them that the laws of physics don’t care about location. Suddenly, one observation generalizes everywhere.
That’s what it means to build symmetry into the learning process rather than hoping the model figures it out.
At the Large Hadron Collider, protons smash together at nearly the speed of light, generating roughly a petabyte of raw data every second. Finding the Higgs boson, hunting for new particles, testing the Standard Model: all of it requires machine learning. But most ML architectures were designed for images or language, not relativistic particle collisions. They can learn the relevant symmetries eventually, but only through brute-force pattern-matching across enormous datasets. In high-energy physics, data is expensive.
A team from Heidelberg University, MIT, IAIFI, and Qualcomm AI Research has built an alternative: the Lorentz Geometric Algebra Transformer (L-GATr), a neural network that speaks the language of special relativity natively.
By encoding Lorentz symmetry directly into the network architecture, L-GATr learns from particle physics data more efficiently and more accurately than architectures that must discover symmetry on their own.
How It Works
The architecture combines three ideas.
First, Lorentz equivariance: the network’s outputs transform predictably when you shift reference frames. In special relativity, all physical laws obey this rule. The mass of a particle doesn’t change whether you measure from a stationary lab or a moving train. Most neural networks violate this implicitly, forcing the model to approximate it from data. L-GATr bakes it in mathematically, so the guarantee is exact by construction. It also handles cases where detector geometry or beam direction breaks perfect Lorentz symmetry.
Second, the representation. Rather than feeding the network plain four-vectors (the energy and momentum coordinates describing each particle), L-GATr encodes everything in the geometric algebra over four-dimensional spacetime. This is like upgrading from speaking only in nouns to having a full grammar: scalars, vectors, bivectors (quantities describing oriented areas in spacetime), and higher-grade objects all live in one unified algebraic structure. The network gets richer building blocks while keeping every computation Lorentz-equivariant. It can naturally capture invariant masses, decay angles, and other quantities physicists care about.
Third, the Transformer backbone. Transformers compute pairwise attention between all inputs (here, all particles in a collision event), making them natural fits for variable-length particle lists. They also support optimized backends like Flash Attention, so L-GATr inherits years of engineering work on large-scale training.
Getting this to work required several new layers built from scratch:
- A maximally expressive Lorentz-equivariant linear map for mixing geometric algebra components
- A Lorentz-equivariant attention mechanism replacing standard dot-product attention
- Lorentz-equivariant layer normalization, which is subtle since naive normalization breaks the symmetry
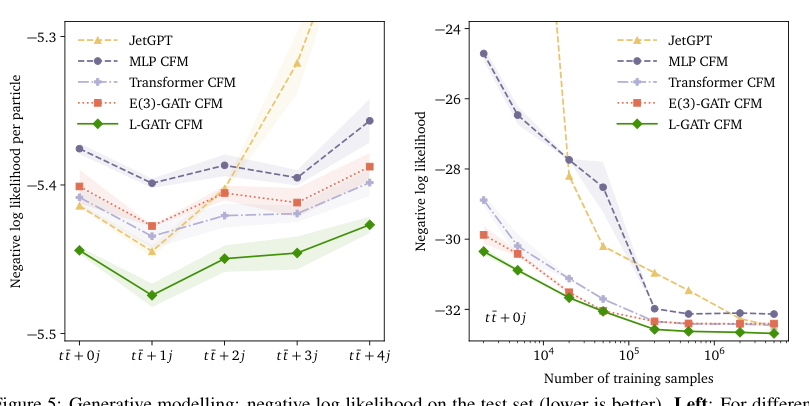
Beyond classification and regression, L-GATr also powers the first Lorentz-equivariant generative model. The approach uses a continuous normalizing flow trained with Riemannian flow matching, a method that respects the curved geometry of particle-physics phase space. This lets the model hard-code the sharp probability boundaries from detector cuts and kinematic constraints, rather than learning them from data.
Why It Matters
The three benchmark tasks span very different parts of the LHC analysis chain. Amplitude surrogates ask the network to mimic complex quantum field theory calculations (a precision regression problem). Top quark tagging is a well-established classification benchmark, distinguishing jets produced by top quarks from background. Generative modeling of reconstructed particles attacks the simulation bottleneck that limits nearly every LHC analysis.
L-GATr matches or outperforms specialized baselines across all three. One general-purpose equivariant architecture replacing a collection of task-specific tools.
That matters because domain-specific models built for one task can’t easily transfer. L-GATr is a single backbone that plugs into the entire analysis pipeline. As collider experiments grow more demanding (the High-Luminosity LHC upgrade will increase collision rates roughly fivefold), data-efficient and versatile architectures become a practical necessity. Building Lorentz symmetry in from the start is as much an engineering advantage as a mathematical one.
There are clear directions to push this further. The current architecture handles the Lorentz group but not the full Poincaré group, which also includes spacetime translations. Long-lived particles that travel measurable distances before decaying would require tracking absolute positions, an extension that is straightforward in principle. The framework could also adapt to other symmetry groups in particle physics: SU(3) color symmetry governs the strong force and has barely been touched by equivariant ML.
L-GATr shows that encoding special relativity’s symmetry directly into a Transformer is both achievable and worth it, matching or beating specialized tools across regression, classification, and generative modeling while remaining a single flexible backbone for LHC analysis.
IAIFI Research Highlights
L-GATr translates the mathematical structure of special relativity into a practical neural network backbone, connecting geometric deep learning with relativistic particle physics across multiple stages of LHC data analysis.
The paper introduces new Lorentz-equivariant attention mechanisms, linear maps, and layer normalization techniques, along with the first equivariant generative model trained with Riemannian flow matching.
By building Lorentz equivariance into a general-purpose architecture, L-GATr improves data efficiency across high-energy physics tasks from quantum amplitude regression to particle-level simulation, targeting key computational bottlenecks at the LHC.
Future work could extend the architecture to the full Poincaré group and gauge symmetries of the Standard Model; the paper is available at [arXiv:2405.14806](https://arxiv.org/abs/2405.14806).
Original Paper Details
Lorentz-Equivariant Geometric Algebra Transformers for High-Energy Physics
2405.14806
Jonas Spinner, Victor Bresó, Pim de Haan, Tilman Plehn, Jesse Thaler, Johann Brehmer
Extracting scientific understanding from particle-physics experiments requires solving diverse learning problems with high precision and good data efficiency. We propose the Lorentz Geometric Algebra Transformer (L-GATr), a new multi-purpose architecture for high-energy physics. L-GATr represents high-energy data in a geometric algebra over four-dimensional space-time and is equivariant under Lorentz transformations, the symmetry group of relativistic kinematics. At the same time, the architecture is a Transformer, which makes it versatile and scalable to large systems. L-GATr is first demonstrated on regression and classification tasks from particle physics. We then construct the first Lorentz-equivariant generative model: a continuous normalizing flow based on an L-GATr network, trained with Riemannian flow matching. Across our experiments, L-GATr is on par with or outperforms strong domain-specific baselines.