
Linearized Wasserstein Barycenters: Synthesis, Analysis, Representational Capacity, and Applications
Authors
Matthew Werenski, Brendan Mallery, Shuchin Aeron, James M. Murphy
Abstract
We propose the linear barycentric coding model (LBCM) which utilizes the linear optimal transport (LOT) metric for analysis and synthesis of probability measures. We provide a closed-form solution to the variational problem characterizing the probability measures in the LBCM and establish equivalence of the LBCM to the set of 2-Wasserstein barycenters in the special case of compatible measures. Computational methods for synthesizing and analyzing measures in the LBCM are developed with finite sample guarantees. One of our main theoretical contributions is to identify an LBCM, expressed in terms of a simple family, which is sufficient to express all probability measures on the closed unit interval. We show that a natural analogous construction of an LBCM in 2 dimensions fails, and we leave it as an open problem to identify the proper extension in more than 1 dimension. We conclude by demonstrating the utility of LBCM for covariance estimation and data imputation.
Concepts
The Big Picture
Imagine you have a collection of musical styles (jazz, classical, blues) and you want to create a new style that blends elements of all three. You could average them crudely, or you could find a smarter interpolation that preserves each style’s essential character.
The same challenge appears whenever researchers work with probability distributions, the mathematical snapshots of how data is spread out. A distribution might describe the range of energies in a particle collision, or the spread of brightness values across an image. How do you meaningfully blend, compress, and reconstruct these data shapes without losing what makes each one distinctive?
This is the domain of optimal transport: what’s the most efficient way to move one pile of sand into the shape of another? Applied to machine learning, this perspective gives us the Wasserstein metric, which measures how different two distributions are by accounting for their overall shape, not just average values. The catch is that computing Wasserstein distances is expensive. Blending distributions this way means solving hard optimization problems that don’t scale well.
A team at Tufts University (Matthew Werenski, Brendan Mallery, Shuchin Aeron, and James M. Murphy) has proposed a framework called the Linear Barycentric Coding Model (LBCM). It captures most of the geometric richness of Wasserstein blending at a fraction of the computational cost, and comes with formal mathematical guarantees.
Key Insight: “Linearizing” optimal transport (converting the curved geometry of probability space into flat, ordinary arithmetic) makes blending distributions as simple as a weighted average. In one dimension, this simplified model turns out to be expressive enough to represent any probability distribution.
How It Works
The central idea rests on Linear Optimal Transport (LOT). You pick a fixed “base measure” as a reference distribution, and LOT assigns every other distribution a coordinate in ordinary flat space by computing the optimal transport map from the base to that distribution. Think of it as giving every data pattern a unique GPS address on a flat map.
Once distributions have flat-space addresses, blending becomes simple. The LBCM defines two complementary operations:
- Synthesis: Given reference distributions and non-negative weights summing to one, produce a new distribution by taking a weighted combination of transport maps applied to the base. The weights live on a simplex, the space of valid weight combinations, like a triangle where each corner represents 100% of one reference distribution.
- Analysis: Given an unknown distribution, find the weights that best reconstruct it from the reference measures.
The payoff: synthesis has a closed-form solution, a single formula with no iterative guessing:
$$\mu_\lambda = \left(\sum_i \lambda_i T^{\mu_i}{\mu_0}\right)# \mu_0$$
The analysis problem reduces to a quadratic program, an optimization with a single guaranteed best answer. It runs in milliseconds, unlike full Wasserstein barycenter methods that require expensive iteration.
The team also proves finite-sample error rates using results on entropy-regularized optimal transport. When you only have samples rather than exact distributions (the common real-world case), estimation error decays at provable rates as sample size grows.
A surprising asymmetry in expressiveness. The headline theoretical result concerns whether LBCM can approximate any probability distribution, not just those near the references.
In one dimension: yes, completely. Theorem 4 shows that reference measures supported on just two points ${a, b}$, with the uniform measure on $[a,b]$ as the base, make the LBCM dense in the space of all probability measures on $[a,b]$. Two endpoints are enough to span all of distribution space.
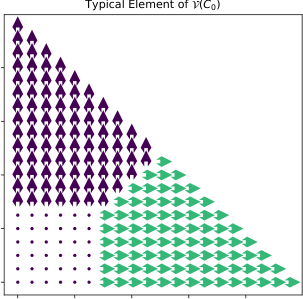
In two dimensions: this fails. Theorem 5 proves the natural generalization (measures on the four corners of a square) cannot approximate all distributions on the square. The intuition is geometric: in 1D, transport maps are monotone rearrangements, a tractable class. In higher dimensions they must satisfy a curl-free condition, which severely restricts what any finite linear span can express. The correct 2D generalization remains an open problem that the authors explicitly flag as unresolved.
Why It Matters
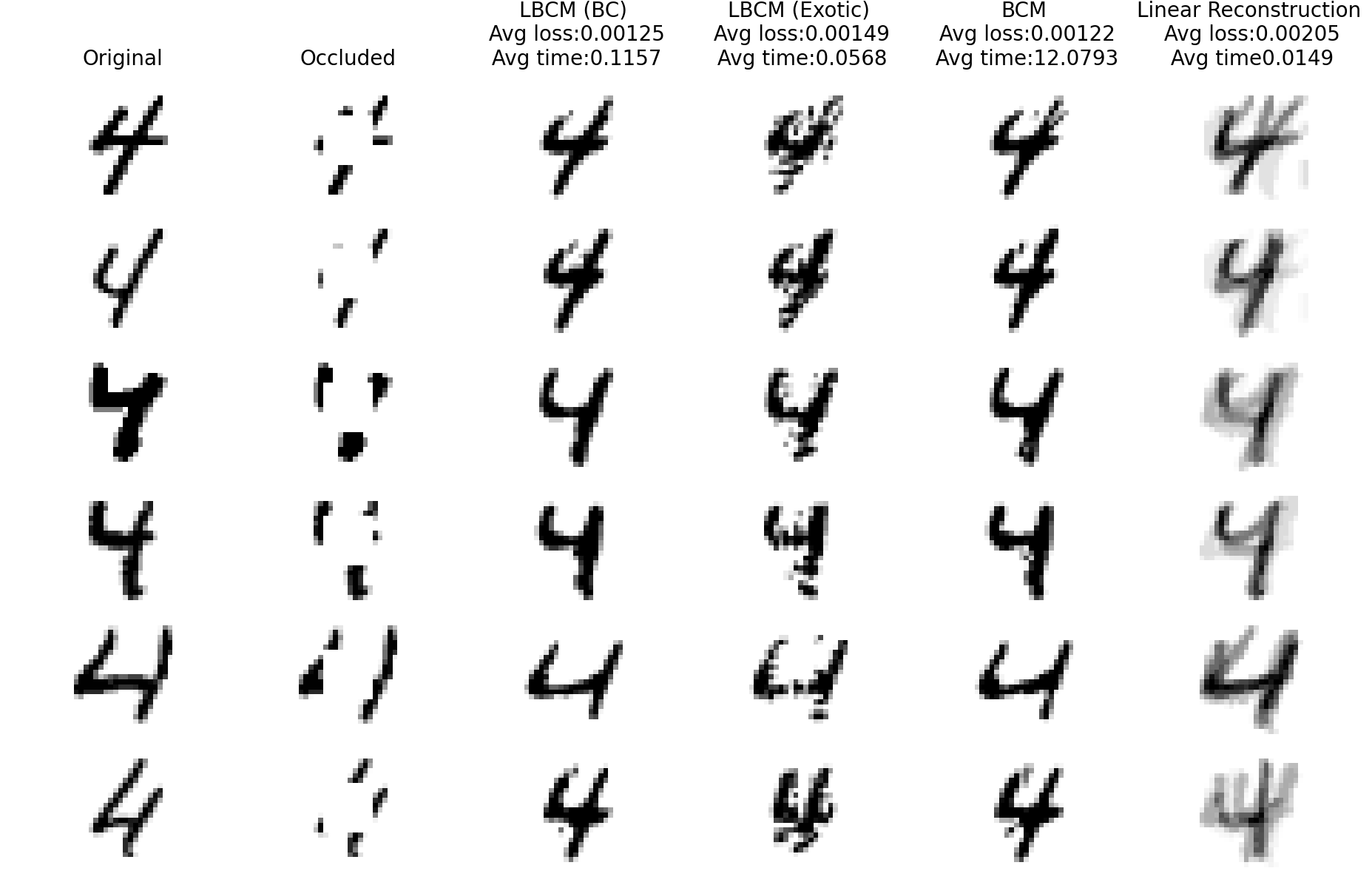
The team validates LBCM on two concrete tasks. For covariance estimation, they represent Gaussian distributions by their covariance matrices and show LBCM can recover missing covariance structure from incomplete observations. For data imputation, they test image reconstruction from partial data. LBCM achieves quality comparable to full Wasserstein barycenter methods while running significantly faster, since the closed-form synthesis replaces iterative solvers.
The experiments also show that base measure choice matters. A well-chosen base improves reconstruction; a poor one degrades it. This sensitivity is a practical consideration, but it gives practitioners a tunable knob for improving performance without changing the model architecture.
Probability distributions show up everywhere in modern AI and physics. In high-energy physics, collision events are distributions over particle momenta. In generative AI, working with data distributions is the whole game. LBCM is fast enough for large-scale applications, grounded in theory, and more faithful to the geometry of probability space than naive averaging.
The open question in higher dimensions is worth watching. Solving it would extend LBCM to images, point clouds, and the multidimensional data native to physics and machine learning. The gap between 1D universality and 2D failure points to deep, unresolved structure in the geometry of transport maps.
Bottom Line: The Linear Barycentric Coding Model turns the hard geometry of Wasserstein space into tractable linear algebra, with closed-form solutions, provable guarantees, and the ability to represent any 1D distribution from just two reference points.
IAIFI Research Highlights
LBCM tackles the general problem of blending and comparing probability distributions, with potential applications to high-energy physics event comparison and other measurement-intensive fields where distributions are the natural data format.
Closed-form synthesis and quadratic-program analysis reduce Wasserstein barycenter computation from expensive iterative methods to fast linear algebra, with provable finite-sample statistical guarantees.
By linearizing the geometry of probability space, LBCM gives physicists scalable tools for comparing and averaging complex event distributions in settings where each observation is itself a distribution over measured quantities.
The open problem of identifying the correct 2D universality construction is a direct path to extending LBCM to images and point clouds; the full paper is available at [arXiv:2410.23602](https://arxiv.org/abs/2410.23602).