
Learning Task Informed Abstractions
Authors
Xiang Fu, Ge Yang, Pulkit Agrawal, Tommi Jaakkola
Abstract
Current model-based reinforcement learning methods struggle when operating from complex visual scenes due to their inability to prioritize task-relevant features. To mitigate this problem, we propose learning Task Informed Abstractions (TIA) that explicitly separates reward-correlated visual features from distractors. For learning TIA, we introduce the formalism of Task Informed MDP (TiMDP) that is realized by training two models that learn visual features via cooperative reconstruction, but one model is adversarially dissociated from the reward signal. Empirical evaluation shows that TIA leads to significant performance gains over state-of-the-art methods on many visual control tasks where natural and unconstrained visual distractions pose a formidable challenge.
Concepts
The Big Picture
Imagine handing a chess grandmaster a photograph of a game board and asking them to plan their next move, but the photo is taken in a crowded coffee shop, full of people, steam, and distracting signage. A human expert filters all of that out instantly. Their brain doesn’t try to memorize every face in the background before deciding to move the knight. AI systems are bad at this.
Show a reinforcement learning (RL) agent (an AI that learns by trial and error, collecting rewards for good actions and penalties for bad ones) a complex visual scene, and it dutifully tries to learn everything it sees: the robot arm, the target object, and every flickering pixel of background scenery.
This is not a minor inconvenience. Real-world robots operate in messy environments with changing lighting, moving people, and reflective surfaces. If the AI spends its limited representational capacity modeling all of that noise, it has less left for what actually matters: figuring out where the arm is and where it needs to go.
Researchers at MIT CSAIL and IAIFI developed Task Informed Abstractions (TIA) to address this head-on. Rather than hoping the agent figures out what to ignore on its own, TIA teaches it to separate signal from clutter by design.
TIA forces a learning system to build two separate internal models: one focused on task-relevant features and one dedicated to distractors. The two are pitted against each other so neither can cheat by mixing the two kinds of information.
How It Works
The team started with a simple experiment. They trained Dreamer, a leading model-based RL algorithm that builds an internal simulation of the world to plan ahead, on the classic Cheetah Run locomotion task. One version had a clean background. The other had complex natural video playing behind the running cheetah. They also varied model size: small (0.5×), medium (1×), and large (2×).
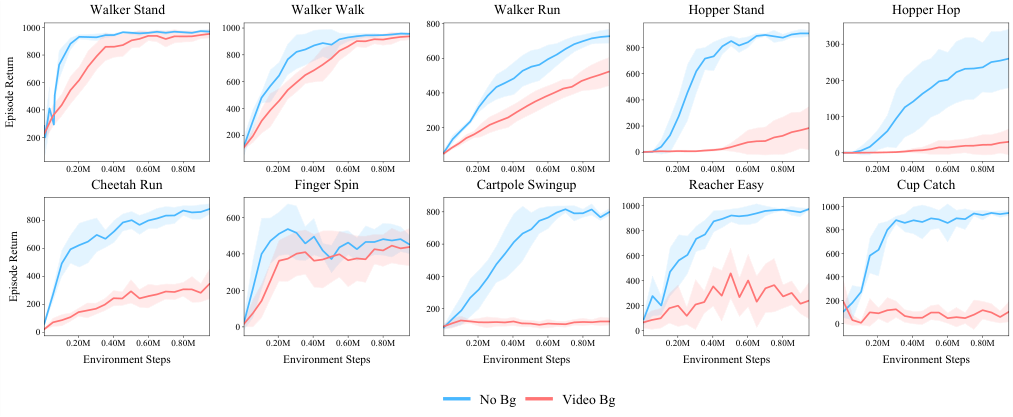
With a clean background, even the smallest model performed well. Adding the complex background caused performance to collapse across all sizes, recovering only as capacity increased. Bigger models weren’t learning better. They were just buying extra capacity to absorb the background and still have some room left for the actual task. Expensive and inelegant.
TIA introduces a formal structure called the Task Informed MDP (TiMDP), which partitions the internal state representation into two components:
- s⁺ (task state): Features correlated with reward, the stuff the agent actually needs to maximize performance.
- s⁻ (distractor state): Everything else: background motion, unrelated objects, visual noise.
Two models work in a cooperative-adversarial game. The task model learns s⁺ by predicting rewards and must capture whatever features matter for success. The distractor model learns s⁻ through a competing mechanism: it is penalized for learning anything correlated with rewards, forcing it to absorb only the leftover visual residual.
Here’s the cooperative part: both models must jointly reconstruct the full observed image. Neither can succeed alone. The task model handles the robot arm; the distractor model handles the moving trees in the background. Together they account for everything the camera captures.
This threads a needle that previous methods missed. Pure reconstruction learning captures too much, encoding every pixel regardless of whether it matters. Pure reward prediction captures too little: knowing only the center of mass of a humanoid is enough to predict reward, but not to control it well. TIA uses reconstruction as a completeness check while using adversarial separation to keep the right features in the right sub-model.
Why It Matters
This problem shows up everywhere. Any domain where an agent must learn from high-dimensional observations littered with visual clutter (medical robotics, scientific instrument control, autonomous vehicles) hits the same wall.
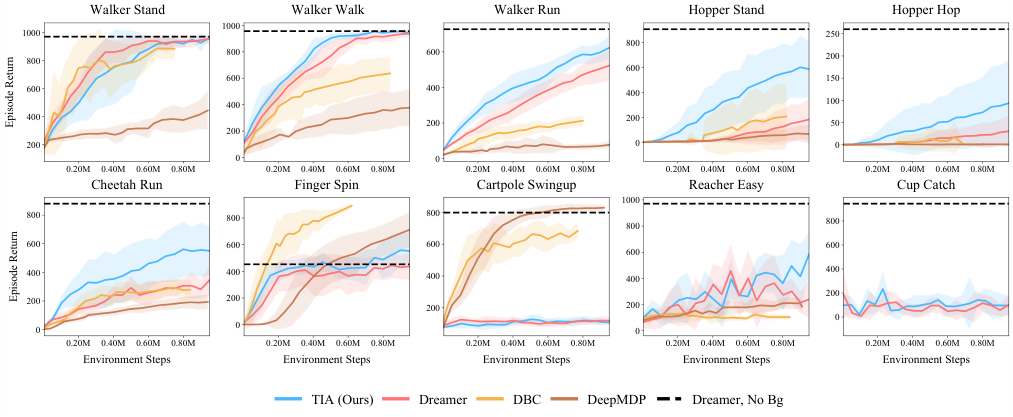
TIA beats prior methods across three distinct evaluation settings:
- The DMControl benchmark, a standard suite of robot control tasks with video distractors
- The custom ManyWorld environment, designed specifically to stress-test distraction robustness
- Atari games, where visual clutter takes a very different form
The gains are largest where distractions are hardest, which is exactly where prior methods struggle most. That’s a sign TIA is solving the right problem, not just tuning hyperparameters on easy cases.
The deeper point isn’t a clever trick but a formalization of something humans do naturally: build mental models that are selective, not exhaustive. Whether TIA can scale to real-world settings where the boundary between “relevant” and “irrelevant” gets fuzzy remains an open question. So does the stability of adversarial training as environments grow more complex. But the framework stands on solid ground.
Bottom Line: TIA teaches AI agents to see like experts, filtering out visual noise not by brute-force capacity but by learning what to ignore. It’s a step toward RL agents that can handle the messy, distraction-filled real world.
IAIFI Research Highlights
TIA applies information-theoretic principles (the physicist's instinct that a good model should capture only the minimal sufficient representation of a system) directly to deep reinforcement learning, connecting statistical mechanics intuition to practical AI agent design.
By formalizing the TiMDP and introducing cooperative-adversarial training to separate task-relevant features from distractors, TIA sets a new state of the art on visual control benchmarks with natural distractions, outperforming leading model-based RL methods by wide margins.
The distractor-separation framework has natural parallels in experimental physics, where extracting meaningful signals from noisy data is the central challenge, whether in particle physics or gravitational wave detection.
Future work may extend TiMDP to continuous, time-varying distractor distributions and real robotic deployment; the full paper is available via the ICML 2021 proceedings, with the arXiv preprint at [arXiv:2106.15612](https://arxiv.org/abs/2106.15612).
Original Paper Details
Learning Task Informed Abstractions
2106.15612
Xiang Fu, Ge Yang, Pulkit Agrawal, Tommi Jaakkola
Current model-based reinforcement learning methods struggle when operating from complex visual scenes due to their inability to prioritize task-relevant features. To mitigate this problem, we propose learning Task Informed Abstractions (TIA) that explicitly separates reward-correlated visual features from distractors. For learning TIA, we introduce the formalism of Task Informed MDP (TiMDP) that is realized by training two models that learn visual features via cooperative reconstruction, but one model is adversarially dissociated from the reward signal. Empirical evaluation shows that TIA leads to significant performance gains over state-of-the-art methods on many visual control tasks where natural and unconstrained visual distractions pose a formidable challenge.