
Infinite Neural Network Quantum States: Entanglement and Training Dynamics
Authors
Di Luo, James Halverson
Abstract
We study infinite limits of neural network quantum states ($\infty$-NNQS), which exhibit representation power through ensemble statistics, and also tractable gradient descent dynamics. Ensemble averages of Renyi entropies are expressed in terms of neural network correlators, and architectures that exhibit volume-law entanglement are presented. A general framework is developed for studying the gradient descent dynamics of neural network quantum states (NNQS), using a quantum state neural tangent kernel (QS-NTK). For $\infty$-NNQS the training dynamics is simplified, since the QS-NTK becomes deterministic and constant. An analytic solution is derived for quantum state supervised learning, which allows an $\infty$-NNQS to recover any target wavefunction. Numerical experiments on finite and infinite NNQS in the transverse field Ising model and Fermi Hubbard model demonstrate excellent agreement with theory. $\infty$-NNQS opens up new opportunities for studying entanglement and training dynamics in other physics applications, such as in finding ground states.
Concepts
The Big Picture
Imagine describing every grain of sand on every beach on Earth, not just each grain’s position, but how it’s entangled with every other grain. That’s roughly the challenge of simulating quantum many-body systems. A quantum state doesn’t just grow bigger as you add particles; it grows exponentially bigger. One more electron doubles the complexity. Ten more and you’re in a different universe of computational difficulty.
Neural network quantum states (NNQS) offer one possible escape hatch. Use a neural network to compactly represent a quantum wavefunction. Neural networks are flexible enough to encode any quantum state, at least in principle. But “in principle” and “in practice” are two different things. How well do they actually encode quantum information? And why does training work when it does, or fail when it doesn’t?
Di Luo and James Halverson at IAIFI tackled these questions by pushing neural network quantum states to a limit: infinite size. Their framework, ∞-NNQS (infinite neural network quantum states), gives the first mathematically exact, solvable picture of how these networks capture quantum correlations and how they learn.
Key Insight: By taking neural networks to infinite width, the authors derive exact, closed-form solutions for quantum state representation and learning dynamics. What was an opaque black box becomes a transparent, solvable system.
How It Works
The central trick comes from a well-known result in machine learning theory: as a neural network grows infinitely wide, its behavior simplifies. The network’s outputs become a Gaussian process (GP), a probability distribution over functions whose statistics are fully determined by simple, computable rules. This is the neural network Gaussian process (NNGP) correspondence, and Luo and Halverson exploit it to study quantum states.
In the NNGP limit, the ensemble of possible wavefunctions has Gaussian statistics. That has direct consequences for entanglement entropy, the quantity measuring how much quantum information is shared between two subsystems.
The authors show that ensemble averages of Rényi entanglement entropies (a family of entropy measures, each capturing a different slice of the correlation structure) can be written in terms of neural network correlators. In the Gaussian limit, these correlators become exactly computable using Wick’s theorem, a quantum field theory technique that reduces complex calculations to products of two-point correlations.
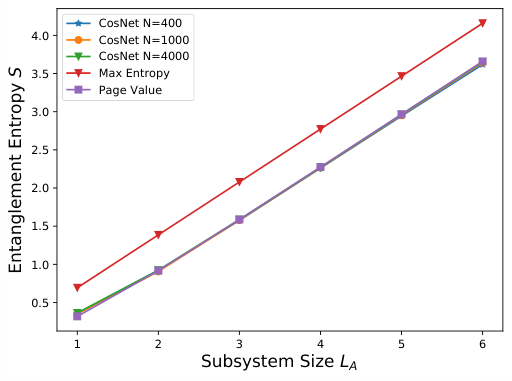
The team analyzes the Cos-net architecture as a worked example, where the wavefunction is built from cosine activations with random weights. In the infinite-width limit, Cos-net’s two-point correlation function takes a clean Gaussian form. Tuning one parameter (σ_w → ∞), the wavefunction ensemble approaches states exhibiting volume-law entanglement, where entanglement grows proportionally to system size. That’s the richest possible entanglement structure.
They tested this prediction numerically using Cos-net networks at widths N = 400, 1000, and 4000. The Von Neumann entanglement entropy converges toward the Page value (the theoretical maximum for random states) as width increases, confirming the theory.
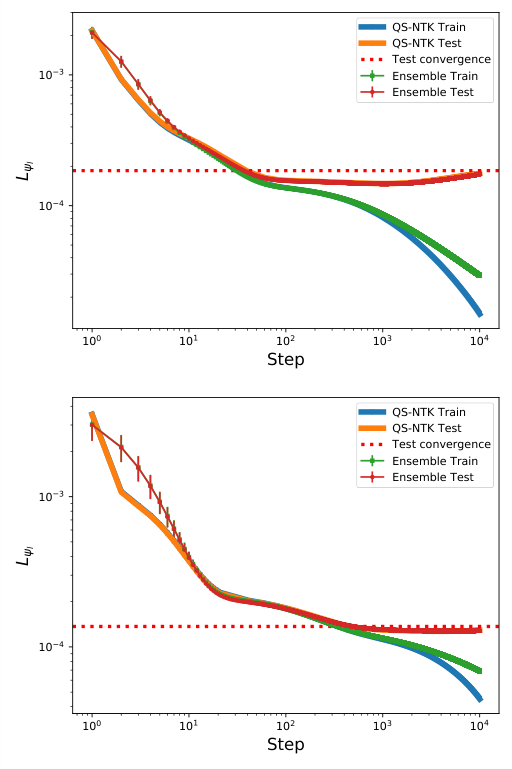
The second half of the paper tackles training. Luo and Halverson introduce the quantum state neural tangent kernel (QS-NTK), which tracks how the wavefunction changes as network parameters are updated during gradient descent.
In general, the QS-NTK depends on the current parameters and evolves during training, making it hard to analyze. At infinite width, though, it becomes deterministic and constant. Gradient descent goes from a complex nonlinear system to a linear ordinary differential equation with an analytic solution.
What does this buy you? For supervised learning of quantum states, where an NNQS is trained to match a target wavefunction, the authors prove that an ∞-NNQS with a well-behaved QS-NTK can recover any target wavefunction exactly. No approximation: a provable guarantee.
- Training dynamics follow an exponential convergence curve, fully determined by the QS-NTK’s eigenvalues
- The QS-NTK computed at initialization accurately predicts training trajectories for finite-width networks, provided widths are large enough
- The same framework covers both ground state optimization and supervised learning within a single mathematical structure, and could extend naturally to tasks like quantum state tomography
The team tested these predictions on two standard models. The transverse field Ising model is a classic testbed for quantum phase transitions. The Fermi Hubbard model is a workhorse of condensed matter theory for strongly correlated electrons. In both cases, finite-width networks converged toward the infinite-width analytic predictions as width increased.
Why It Matters
This work lands squarely at the intersection of two fields. On the AI side, it extends the neural tangent kernel framework into quantum physics. The QS-NTK isn’t a straightforward transplant: quantum wavefunctions are complex-valued and must be normalized, which introduces subtleties that required new mathematical treatment.
On the physics side, analytically characterizing entanglement in NNQS ensembles opens up something like entanglement engineering. Physicists studying topological phases, quantum error correction, or many-body ground states could choose neural network architectures to match desired entanglement patterns. Finite-width corrections introduce non-Gaussianities beyond the infinite limit, suggesting a range of entanglement behaviors accessible by tuning architecture and width.
Bottom Line: Infinite neural network quantum states give physicists their first complete analytic handle on both the entanglement structure and training dynamics of NNQS, putting a promising but poorly understood tool on solid theoretical footing.
IAIFI Research Highlights
This work combines neural tangent kernel theory from machine learning with entanglement entropy calculations from quantum physics, producing results that neither field could have reached alone.
The QS-NTK extends deep learning theory to complex-valued, normalized function spaces, with provable convergence guarantees for a new class of learning problems.
Analytically characterizing volume-law entanglement in ∞-NNQS points toward new approaches for studying strongly correlated quantum matter and designing quantum representations with specific entanglement properties.
Next steps include applying ∞-NNQS to ground state optimization and exploring how finite-width non-Gaussianities shape entanglement in physically relevant systems; the full paper is available at [arXiv:2112.00723](https://arxiv.org/abs/2112.00723).
Original Paper Details
Infinite Neural Network Quantum States: Entanglement and Training Dynamics
2112.00723
Di Luo, James Halverson
We study infinite limits of neural network quantum states ($\infty$-NNQS), which exhibit representation power through ensemble statistics, and also tractable gradient descent dynamics. Ensemble averages of Renyi entropies are expressed in terms of neural network correlators, and architectures that exhibit volume-law entanglement are presented. A general framework is developed for studying the gradient descent dynamics of neural network quantum states (NNQS), using a quantum state neural tangent kernel (QS-NTK). For $\infty$-NNQS the training dynamics is simplified, since the QS-NTK becomes deterministic and constant. An analytic solution is derived for quantum state supervised learning, which allows an $\infty$-NNQS to recover any target wavefunction. Numerical experiments on finite and infinite NNQS in the transverse field Ising model and Fermi Hubbard model demonstrate excellent agreement with theory. $\infty$-NNQS opens up new opportunities for studying entanglement and training dynamics in other physics applications, such as in finding ground states.