
Improved Distribution Matching Distillation for Fast Image Synthesis
Authors
Tianwei Yin, Michaël Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, William T. Freeman
Abstract
Recent approaches have shown promises distilling diffusion models into efficient one-step generators. Among them, Distribution Matching Distillation (DMD) produces one-step generators that match their teacher in distribution, without enforcing a one-to-one correspondence with the sampling trajectories of their teachers. However, to ensure stable training, DMD requires an additional regression loss computed using a large set of noise-image pairs generated by the teacher with many steps of a deterministic sampler. This is costly for large-scale text-to-image synthesis and limits the student's quality, tying it too closely to the teacher's original sampling paths. We introduce DMD2, a set of techniques that lift this limitation and improve DMD training. First, we eliminate the regression loss and the need for expensive dataset construction. We show that the resulting instability is due to the fake critic not estimating the distribution of generated samples accurately and propose a two time-scale update rule as a remedy. Second, we integrate a GAN loss into the distillation procedure, discriminating between generated samples and real images. This lets us train the student model on real data, mitigating the imperfect real score estimation from the teacher model, and enhancing quality. Lastly, we modify the training procedure to enable multi-step sampling. We identify and address the training-inference input mismatch problem in this setting, by simulating inference-time generator samples during training time. Taken together, our improvements set new benchmarks in one-step image generation, with FID scores of 1.28 on ImageNet-64x64 and 8.35 on zero-shot COCO 2014, surpassing the original teacher despite a 500X reduction in inference cost. Further, we show our approach can generate megapixel images by distilling SDXL, demonstrating exceptional visual quality among few-step methods.
Concepts
The Big Picture
Say you want to teach a student by having them watch an expert work through every step of a complex problem. Thousands of steps, repeated millions of times. Now suppose that student could distill all of that watching into a single, instantaneous answer that’s actually better than their teacher’s. That’s DMD2 in a nutshell.
Diffusion models, the engine behind tools like Stable Diffusion and DALL-E, create images by starting with random noise and progressively refining it over dozens of cleanup steps. Each step reruns the full AI model from scratch, so high-resolution image generation gets slow and expensive. The race to compress these heavy models into one-step generators has been going on for a while.
A team from MIT and Adobe Research has now pulled it off more convincingly than prior attempts, achieving image quality that surpasses the original teacher model while cutting inference cost by 500x.
Key Insight: DMD2 trains a fast image generator to match the output of a slow, high-quality diffusion model. It adds adversarial training against real photos and a two-speed training schedule, eliminating expensive pre-generated datasets and producing one-step generators that actually outperform the slow models they learned from.
How It Works
The original Distribution Matching Distillation (DMD) had a clever core idea: instead of teaching a student to mimic the teacher’s exact step-by-step path from noise to image, train it to match the teacher’s output distribution. Not the individual trajectories, but the statistical profile of what good images look like. Think of it as learning to paint sunsets without memorizing the master’s exact brushstrokes, just absorbing what makes a sunset work.
But DMD had a weakness. To keep training stable, it required a regression loss computed from millions of pre-generated noise-image pairs, forcing the student to memorize specific teacher trajectories. Generating those pairs is expensive. Worse, it caps the student’s quality, because the student can never exceed what the teacher produces along those fixed paths.
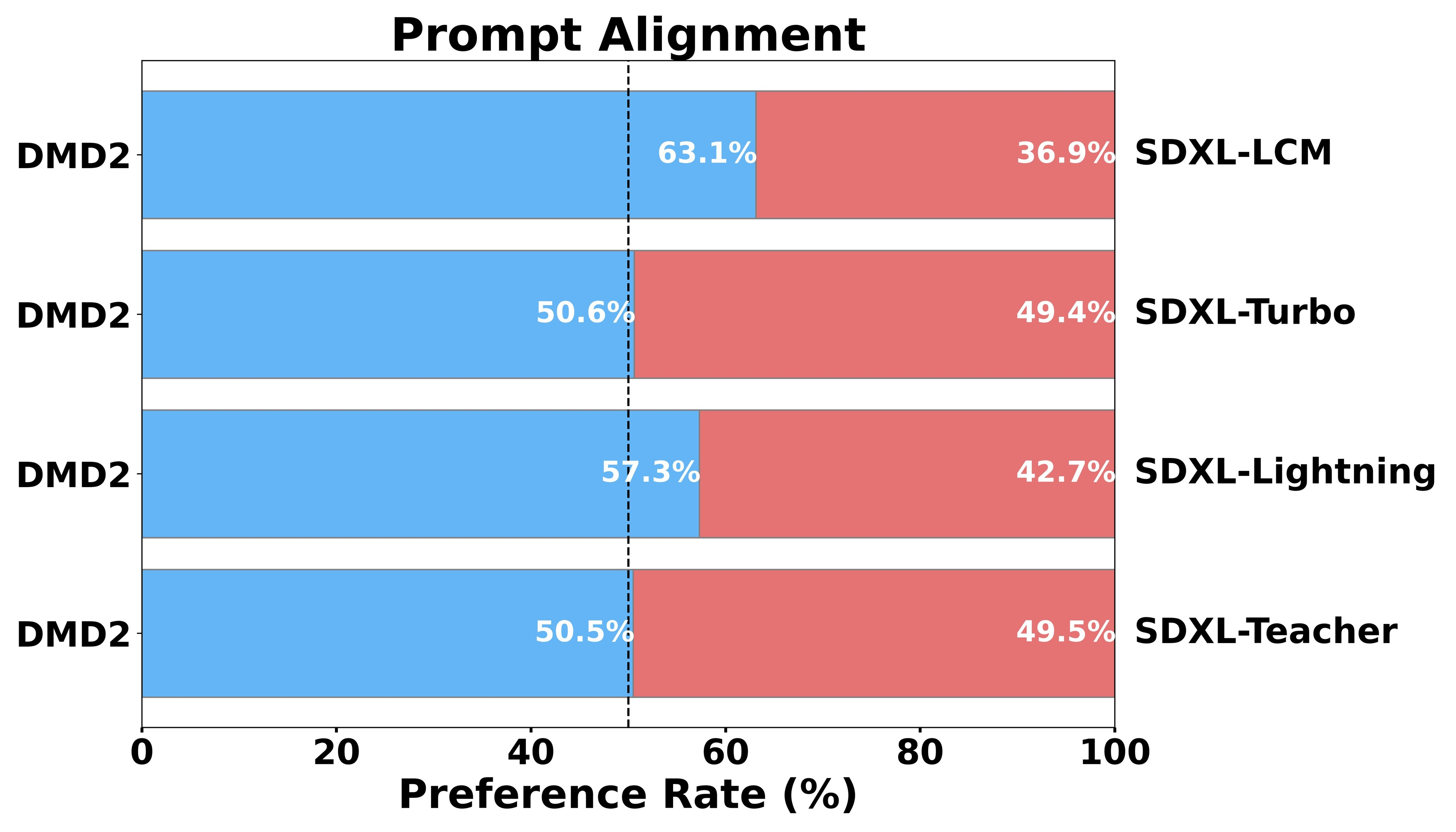
DMD2 removes this requirement through three linked improvements.
Two Time-Scale Update Rule. Without the regression loss, training becomes unstable. The “fake critic” network (a separate model monitoring where the student tends to generate images) falls behind and gives inaccurate feedback. The fix: update the critic more frequently than the generator. Letting the critic catch up before each generator update keeps the feedback signal accurate, and training stabilizes without any pre-computed data.
GAN Loss on Real Images. The researchers added an adversarial objective borrowed from Generative Adversarial Networks (GANs), where a discriminator learns to tell fake images from real ones. The teacher model’s understanding of real data is inherently approximate, but real images are ground truth. Training against actual photographs lets the student correct for the teacher’s errors and produce sharper results.
Backward Simulation for Multi-Step Sampling. The original DMD only supported one-step generation. DMD2 extends this to 2–4 steps, but doing so naively creates a training-inference mismatch: during training the model sees inputs from one distribution, while during inference it encounters a different one. The solution runs the generator itself to produce the noisy intermediate samples used during training, so the model practices on exactly the kind of inputs it will see at test time.
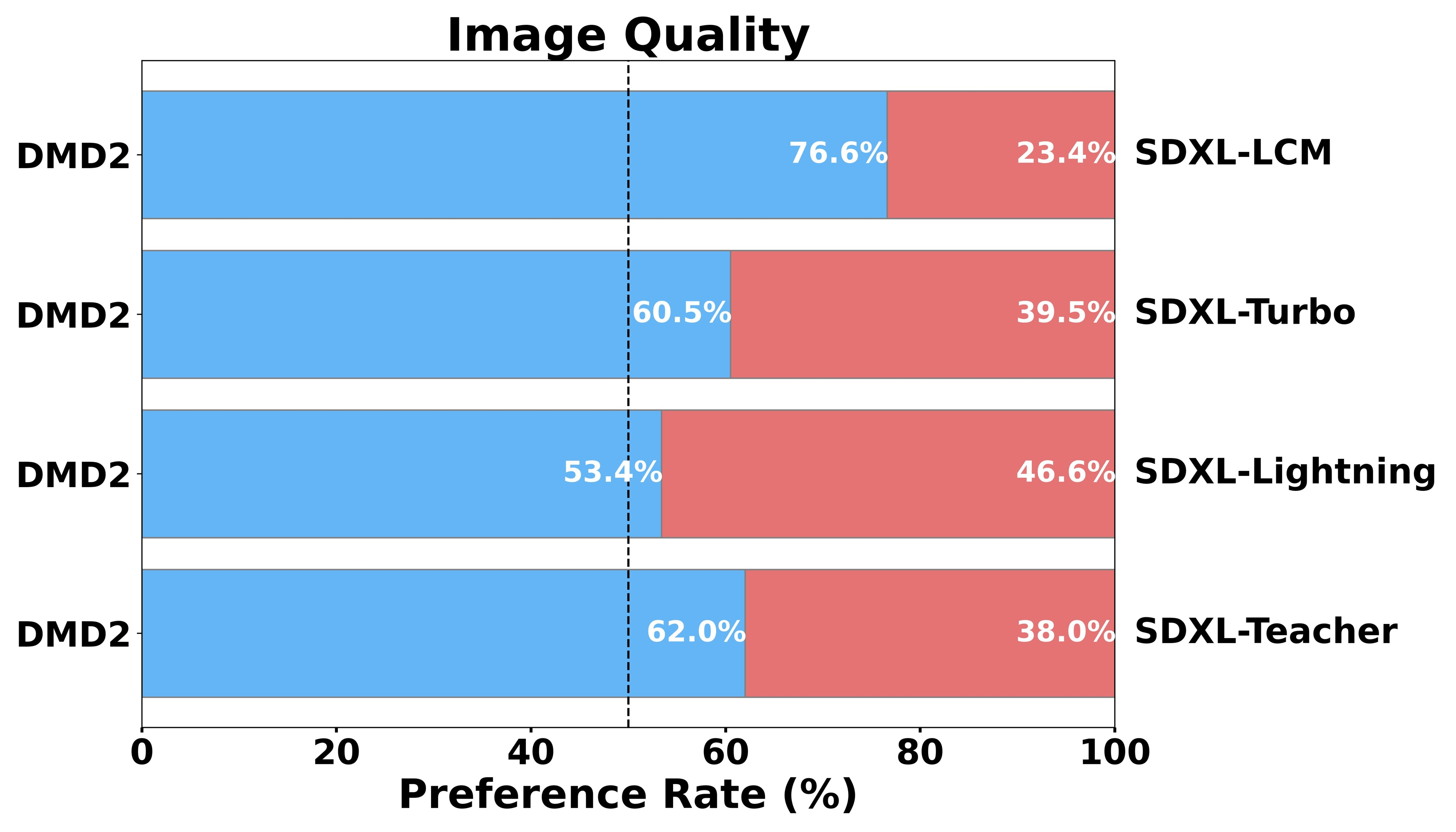
Mathematically, DMD2 minimizes an approximate KL divergence between the student generator’s outputs and the teacher’s approximation of real images. The gradient of this divergence decomposes into two score functions: one pointing toward the real image distribution, one characterizing where the student currently generates. The GAN loss sharpens the first signal with actual ground-truth photos. The two-timescale rule keeps the second signal accurate.
Why It Matters
DMD2 achieves an FID score of 1.28 on ImageNet-64×64 in one step. FID measures how close generated images are to real ones (lower is better). The original teacher diffusion model scores around 2.0 on the same benchmark. The student beats the teacher with 500x less compute.
On zero-shot COCO 2014, the standard text-to-image benchmark, DMD2 scores 8.35, again outperforming its teacher.

The team also distilled SDXL, one of the most capable open text-to-image models, showing that DMD2 scales to megapixel resolution. The 4-step SDXL distillation produces images with strong visual quality, competitive with or exceeding methods that require far more computation.
A 500x speedup doesn’t just make things faster. It makes previously impractical applications viable: real-time creative tools, large-scale synthetic dataset generation, interactive editing workflows. The core idea, that matching a system’s output is often easier than mimicking its process, should carry over wherever a slow model needs a fast stand-in. Video synthesis, 3D generation, and scientific simulation are all on the table.
Bottom Line: DMD2 proves that one-step image generators don’t have to compromise quality. By combining two-timescale training, adversarial objectives on real data, and backward simulation, the student model exceeds its teacher at 1/500th the inference cost.
IAIFI Research Highlights
This work connects generative AI with theoretical ideas from optimal transport and divergence minimization, putting rigorous math to work on the practical problem of making large models affordable to run.
DMD2 sets new records for one-step and few-step image generation, showing that distribution-matching distillation with adversarial training and two-timescale updates can surpass teacher diffusion models at 500x lower inference cost.
Fast, high-quality generative models speed up scientific workflows in physics and astronomy, where simulation-based inference and synthetic data generation are increasingly common.
Future work may extend DMD2's backward simulation and GAN-augmented distillation to video generation and 3D synthesis. The full approach is described in [arXiv:2405.14867](https://arxiv.org/abs/2405.14867).
Original Paper Details
Improved Distribution Matching Distillation for Fast Image Synthesis
2405.14867
Tianwei Yin, Michaël Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, William T. Freeman
Recent approaches have shown promises distilling diffusion models into efficient one-step generators. Among them, Distribution Matching Distillation (DMD) produces one-step generators that match their teacher in distribution, without enforcing a one-to-one correspondence with the sampling trajectories of their teachers. However, to ensure stable training, DMD requires an additional regression loss computed using a large set of noise-image pairs generated by the teacher with many steps of a deterministic sampler. This is costly for large-scale text-to-image synthesis and limits the student's quality, tying it too closely to the teacher's original sampling paths. We introduce DMD2, a set of techniques that lift this limitation and improve DMD training. First, we eliminate the regression loss and the need for expensive dataset construction. We show that the resulting instability is due to the fake critic not estimating the distribution of generated samples accurately and propose a two time-scale update rule as a remedy. Second, we integrate a GAN loss into the distillation procedure, discriminating between generated samples and real images. This lets us train the student model on real data, mitigating the imperfect real score estimation from the teacher model, and enhancing quality. Lastly, we modify the training procedure to enable multi-step sampling. We identify and address the training-inference input mismatch problem in this setting, by simulating inference-time generator samples during training time. Taken together, our improvements set new benchmarks in one-step image generation, with FID scores of 1.28 on ImageNet-64x64 and 8.35 on zero-shot COCO 2014, surpassing the original teacher despite a 500X reduction in inference cost. Further, we show our approach can generate megapixel images by distilling SDXL, demonstrating exceptional visual quality among few-step methods.