
Identifying Tidal Disruption Events with an Expansion of the FLEET Machine Learning Algorithm
Authors
Sebastian Gomez, V. Ashley Villar, Edo Berger, Suvi Gezari, Sjoert van Velzen, Matt Nicholl, Peter K. Blanchard, Kate. D. Alexander
Abstract
We present an expansion of FLEET, a machine learning algorithm optimized to select transients that are most likely to be tidal disruption events (TDEs). FLEET is based on a random forest algorithm trained on the light curves and host galaxy information of 4,779 spectroscopically classified transients. For transients with a probability of being a TDE, \ptde$>0.5$, we can successfully recover TDEs with a $\approx40$\% completeness and a $\approx30$\% purity when using the first 20 days of photometry, or a similar completeness and $\approx50$\% purity when including 40 days of photometry. We find that the most relevant features for differentiating TDEs from other transients are the normalized host separation, and the light curve $(g-r)$ color during peak. Additionally, we use FLEET to produce a list of the 39 most likely TDE candidates discovered by the Zwicky Transient Facility that remain currently unclassified. We explore the use of FLEET for the Legacy Survey of Space and Time on the Vera C. Rubin Observatory (\textit{Rubin}) and the \textit{Nancy Grace Roman Space Telescope} (\textit{Roman}). We simulate the \textit{Rubin} and \textit{Roman} survey strategies and estimate that $\sim 10^4$ TDEs could be discovered every year by \textit{Rubin}, and $\sim200$ TDEs per year by \textit{Roman}. Finally, we run FLEET on the TDEs in our \textit{Rubin} survey simulation and find that we can recover $\sim 30$\% of those at a redshift $z <0.5$ with \ptde$>0.5$. This translates to $\sim3,000$ TDEs per year that FLEET could uncover from \textit{Rubin}. FLEET is provided as a open source package on GitHub https://github.com/gmzsebastian/FLEET
Concepts
The Big Picture
Imagine a star drifting through its galaxy and then, without warning, crossing an invisible boundary around a supermassive black hole. Within hours, gravity tears the star apart. Half the debris gets flung outward; the rest spirals inward, igniting a flare visible across billions of light-years. These stellar deaths are called tidal disruption events (TDEs), and they are among the rarest cosmic events we can observe.
The problem is finding them. Modern sky surveys like the Zwicky Transient Facility (ZTF), which scans the entire northern sky every few nights, discover thousands of short-lived cosmic events called transients every month: supernovae, active galactic nuclei (galaxies with unusually bright, actively feeding black holes at their centers), stellar flares, and more. TDEs make up only about 0.5% of all spectroscopically confirmed transients, those identified through detailed spectral analysis of their light.
Sorting through this haystack by hand doesn’t scale. Spectroscopic follow-up, the gold standard for identification where a telescope spreads an object’s light into its component colors to reveal its true nature, covers only about 10% of discoveries. The Vera C. Rubin Observatory is set to increase the transient discovery rate by roughly a factor of a hundred, so the bottleneck is about to get much worse.
A team led by Sebastian Gomez at the Space Telescope Science Institute has expanded FLEET, a machine learning algorithm originally built to hunt superluminous supernovae, into a TDE classifier that can sift through thousands of candidates and flag the most promising ones in hours.
Key Insight: By training on nearly 5,000 real classified transients and combining light curve shapes with host galaxy context, FLEET can identify likely TDEs up to two orders of magnitude more efficiently than random selection, and it runs on next-generation survey data out of the box.
How It Works
FLEET is built on a random forest algorithm, an ensemble method that constructs hundreds of decision trees (each a chain of yes/no questions about the data) and aggregates their votes into a probability score. The algorithm trains exclusively on real, spectroscopically confirmed events rather than simulations, which often fail when applied to actual observations.
The training set contains 4,779 classified transients, of which 45 are confirmed TDEs. That deliberate imbalance mirrors how rare TDEs actually are. Each transient contributes two categories of features:
- Light curve features: how an event brightens and fades over time, including rise and fade timescales, and the $(g-r)$ color at peak brightness (how much brighter the object appears through a green filter versus a red one, a proxy for temperature)
- Host galaxy features: the transient’s offset from its host galaxy center, galaxy brightness, and photometric redshift estimates (distance approximations derived from galaxy color, without requiring a full spectrum)
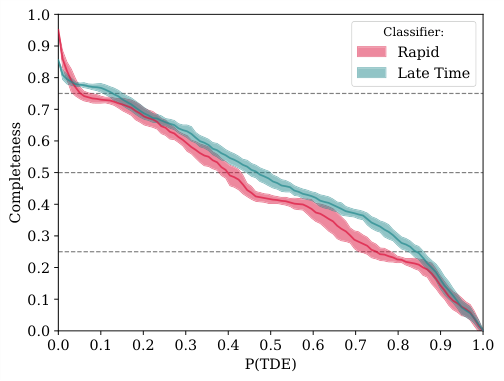
The single most powerful discriminator is the normalized host separation, which measures how far a transient sits from its galaxy’s center relative to the galaxy’s size. TDEs occur when stars wander too close to a central supermassive black hole, so genuine TDEs cluster tightly at their host nuclei. A transient sitting far off-center is almost certainly something else. The second most important feature is $(g-r)$ color at peak: TDE optical emission tends to run bluer than most supernovae of comparable brightness.
With just 20 days of photometry and a threshold of $P(\text{TDE}) > 0.5$, FLEET achieves roughly 40% completeness (finding 40% of true TDEs) at 30% purity (30% of flagged candidates are genuine). Extending to 40 days of photometry pushes purity to around 50% with comparable completeness. At a stricter threshold of $P(\text{TDE}) > 0.8$, purity reaches 80%, which matters when telescope time is too precious to waste on false positives.
The team also ran FLEET across the full ZTF archive and identified 39 currently unclassified transients as strong TDE candidates. That list is ready for observers looking to expand the confirmed sample.
Why It Matters
Rubin’s Legacy Survey of Space and Time (LSST) is expected to discover roughly $10^4$ well-observed TDEs per year, more than the entire confirmed TDE catalog accumulated over decades. Without a photometric classifier running in real time, most of them will go unnoticed.
Simulations of Rubin’s survey cadence show that FLEET can recover about 30% of TDEs at redshifts below $z < 0.5$ (the relatively nearby universe, within roughly 5 billion light-years). That translates to around 3,000 TDE identifications per year from Rubin’s data stream alone. The Nancy Grace Roman Space Telescope, operating at higher redshift, should add around 200 more per year.
A larger TDE sample bears directly on the open questions in the field. How frequently do stars get disrupted? How do disruption rates vary with black hole mass and host galaxy type? What determines whether a TDE produces radio jets, X-ray flares, or only optical emission? Every confirmed TDE is a window into accretion physics, the process of gas and stellar debris spiraling into a black hole under extreme conditions. FLEET widens that window considerably. The algorithm is open source and available on GitHub.
Bottom Line: FLEET turns photometric classification from a bottleneck into a multiplier, letting the coming flood of transient data from Rubin and Roman yield thousands of new TDE discoveries per year. Each one probes supermassive black hole physics that would otherwise go unrecognized.
IAIFI Research Highlights
This paper applies random forest machine learning to astrophysical transient classification, training on real observational data to tackle a core challenge in time-domain astronomy at the boundary of AI and black hole physics.
FLEET shows that ensemble ML methods trained on imbalanced, real-world datasets (rather than simulations) can achieve classification purity nearly two orders of magnitude above random selection.
Identifying TDEs in bulk accelerates the statistical study of supermassive black hole demographics, accretion physics, and stellar dynamics at galactic centers.
With Rubin set to deliver massive volumes of transient alerts in the mid-2020s, FLEET is well suited to serve as a real-time discovery tool; the full paper and open-source code are available at [arXiv:2210.10810](https://arxiv.org/abs/2210.10810) and https://github.com/gmzsebastian/FLEET.
Original Paper Details
Identifying Tidal Disruption Events with an Expansion of the FLEET Machine Learning Algorithm
2210.10810
["Sebastian Gomez", "V. Ashley Villar", "Edo Berger", "Suvi Gezari", "Sjoert van Velzen", "Matt Nicholl", "Peter K. Blanchard", "Kate. D. Alexander"]
We present an expansion of FLEET, a machine learning algorithm optimized to select transients that are most likely to be tidal disruption events (TDEs). FLEET is based on a random forest algorithm trained on the light curves and host galaxy information of 4,779 spectroscopically classified transients. For transients with a probability of being a TDE, \ptde$>0.5$, we can successfully recover TDEs with a $\approx40$\% completeness and a $\approx30$\% purity when using the first 20 days of photometry, or a similar completeness and $\approx50$\% purity when including 40 days of photometry. We find that the most relevant features for differentiating TDEs from other transients are the normalized host separation, and the light curve $(g-r)$ color during peak. Additionally, we use FLEET to produce a list of the 39 most likely TDE candidates discovered by the Zwicky Transient Facility that remain currently unclassified. We explore the use of FLEET for the Legacy Survey of Space and Time on the Vera C. Rubin Observatory (\textit{Rubin}) and the \textit{Nancy Grace Roman Space Telescope} (\textit{Roman}). We simulate the \textit{Rubin} and \textit{Roman} survey strategies and estimate that $\sim 10^4$ TDEs could be discovered every year by \textit{Rubin}, and $\sim200$ TDEs per year by \textit{Roman}. Finally, we run FLEET on the TDEs in our \textit{Rubin} survey simulation and find that we can recover $\sim 30$\% of those at a redshift $z <0.5$ with \ptde$>0.5$. This translates to $\sim3,000$ TDEs per year that FLEET could uncover from \textit{Rubin}. FLEET is provided as a open source package on GitHub https://github.com/gmzsebastian/FLEET