
Growing Brains: Co-emergence of Anatomical and Functional Modularity in Recurrent Neural Networks
Authors
Ziming Liu, Mikail Khona, Ila R. Fiete, Max Tegmark
Abstract
Recurrent neural networks (RNNs) trained on compositional tasks can exhibit functional modularity, in which neurons can be clustered by activity similarity and participation in shared computational subtasks. Unlike brains, these RNNs do not exhibit anatomical modularity, in which functional clustering is correlated with strong recurrent coupling and spatial localization of functional clusters. Contrasting with functional modularity, which can be ephemerally dependent on the input, anatomically modular networks form a robust substrate for solving the same subtasks in the future. To examine whether it is possible to grow brain-like anatomical modularity, we apply a recent machine learning method, brain-inspired modular training (BIMT), to a network being trained to solve a set of compositional cognitive tasks. We find that functional and anatomical clustering emerge together, such that functionally similar neurons also become spatially localized and interconnected. Moreover, compared to standard $L_1$ or no regularization settings, the model exhibits superior performance by optimally balancing task performance and network sparsity. In addition to achieving brain-like organization in RNNs, our findings also suggest that BIMT holds promise for applications in neuromorphic computing and enhancing the interpretability of neural network architectures.
Concepts
The Big Picture
Think about how your brain handles language. One region processes sound, another handles grammar, another manages meaning. These regions are physically close to their collaborators, wired together with short, efficient connections. Now imagine the same computations, but with the relevant neurons scattered randomly across your skull with no spatial logic. The computations might still work, but the organization would be fragile, inefficient, and nearly impossible to understand from the outside.
That’s the problem with modern recurrent neural networks. When trained on complex tasks, these networks do develop functional modularity: groups of neurons activate together on related subtasks, each cluster acting like a specialist team. But these teams float freely. Disconnected from any spatial structure, neurons doing the same job can sit on opposite ends of the network, connected by long-range wires. Brains don’t work that way.
Researchers at MIT and IAIFI asked a pointed question: can we grow artificial neural networks that organize themselves the way brains do, with function and anatomy locked together? Using a technique called brain-inspired modular training (BIMT), they show the answer is yes.
By adding spatial constraints to training, both functional and anatomical modularity emerge together. The networks end up more brain-like, more interpretable, and better at their tasks.
How It Works
The team trained recurrent neural networks (RNNs) on 20-Cog-tasks, a benchmark of 20 cognitive tasks inspired by experiments with rodents and non-human primates. RNNs feed signals back into themselves over time, making them a natural fit for sequential tasks. Each task in the benchmark combines simpler computational subtasks drawn from a shared pool, so an optimal network should specialize neuron groups for each subtask and reuse them across tasks.
Standard training with L1 regularization, which penalizes large weights to push networks toward sparser solutions, does produce functional modularity. But the functionally similar neurons scatter randomly across the network. No spatial rhyme or reason.
BIMT changes this by treating neurons as physical objects embedded in 2D space. The hidden layer of 400 neurons lives on a 20×20 grid, and every connection carries a cost proportional to the distance it spans. The total loss function has three components:
- Prediction loss: how well the network solves the cognitive tasks
- L1 regularization: standard sparsity penalty on all weights
- Distance-aware regularization: an additional penalty proportional to weight magnitude times the physical distance between connected neurons
This distance penalty creates pressure for neurons to cluster near their collaborators. But gradient descent alone gets stuck: a network initialized with non-local connections would stay that way.
So BIMT adds a second mechanism, neuron swapping. During training, pairs of neurons are tested to see if exchanging their grid positions would reduce total wiring cost. If yes, they swap. This discrete rearrangement lets the network escape local minima and find genuinely compact spatial configurations.
The result: neurons that fire together don’t just wire together. They move together.
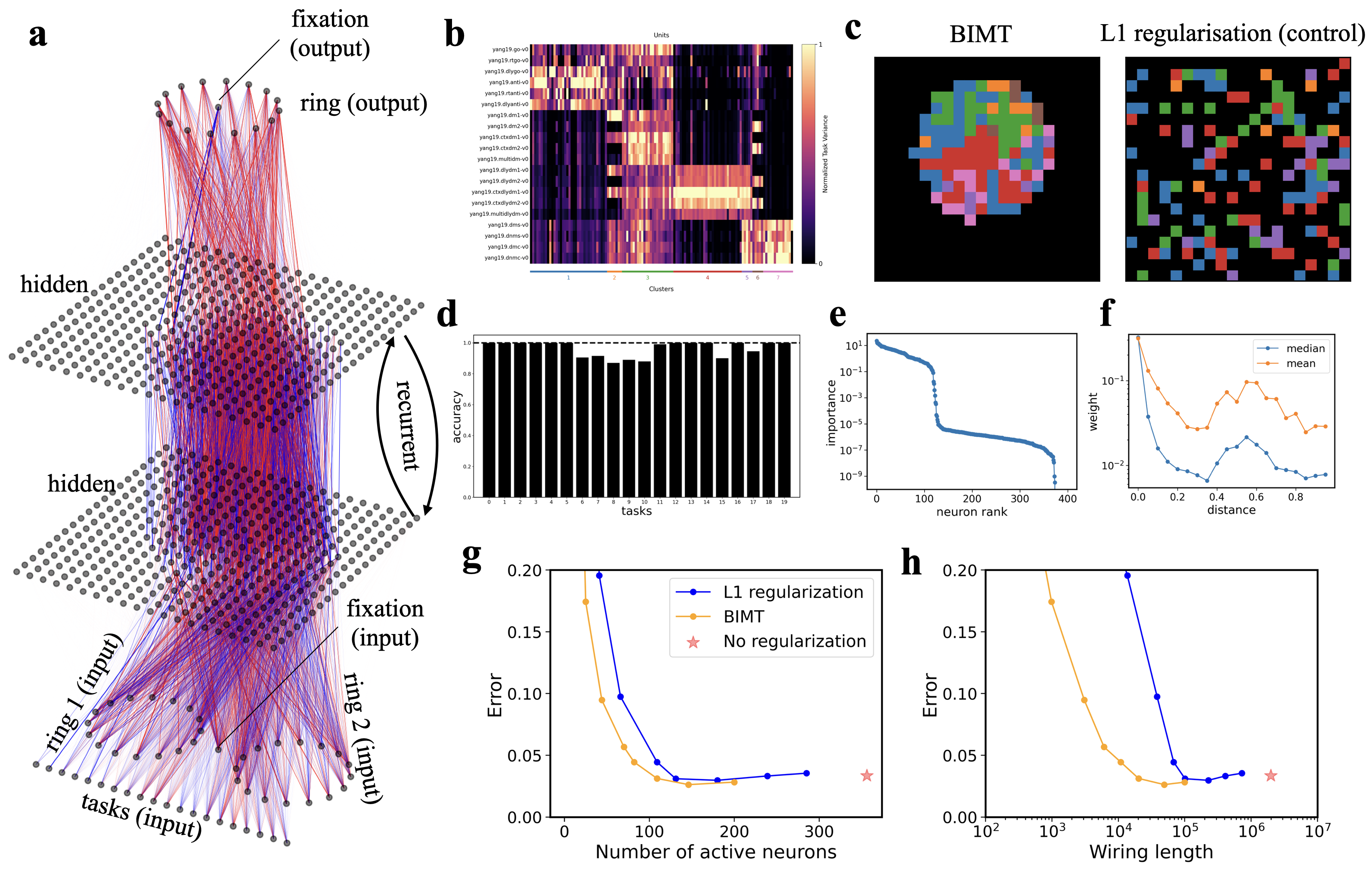
After training, the hidden layer develops spatial structure resembling a simplified brain map. Neurons specializing in the same subtask cluster into distinct spatial patches, connected densely within each patch and sparsely across patches.
The paper quantifies this with two metrics: a modularity score measuring how well neurons cluster by function, and a locality score measuring how spatially concentrated each cluster is. BIMT consistently achieves high scores on both. Standard L1 achieves functional modularity but nearly zero anatomical modularity.
The performance-sparsity tradeoff is where BIMT pulls ahead. It sits on a better Pareto frontier than either L1 or no regularization. For the same sparsity level, BIMT networks make fewer errors. For the same error rate, they use fewer active neurons and shorter total wiring.
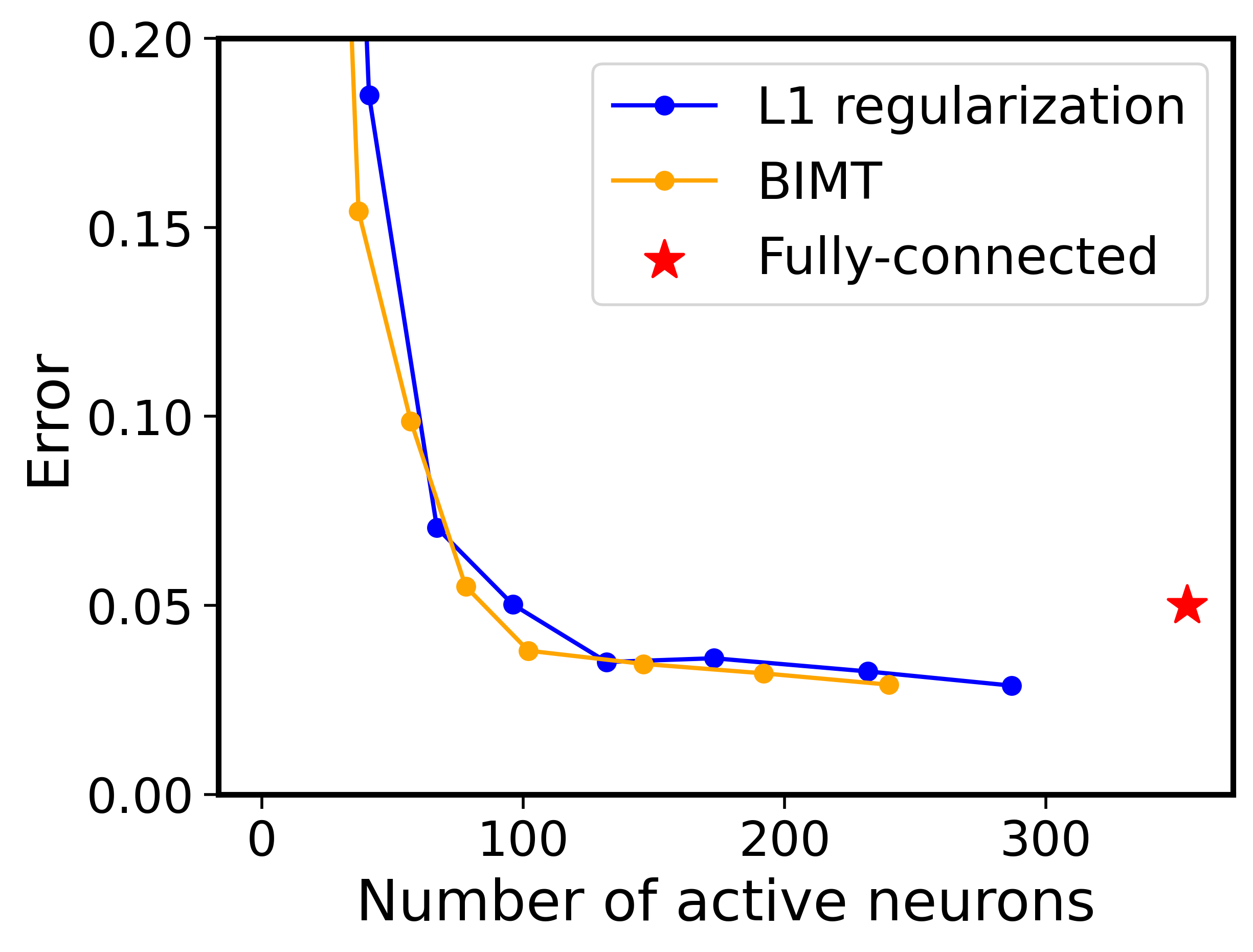
Spatial pressure pushes the network toward representations that are both compact and reusable, which is exactly what you need for generalizing to new combinations of familiar subtasks. A second benchmark, Mod-Cog-tasks, showed the same pattern.
Why It Matters
For neuroscience, this is a clean proof of principle. Spatial wiring constraints alone, without genetics, developmental biology, or evolutionary history, are enough to produce both functional and anatomical modularity at once. That lends weight to theories that the brain’s modular geography arises partly from the simple physics of minimizing wiring costs.
Anatomical modularity is also more durable than the purely functional kind. When incoming data patterns change, functional clusters can dissolve. Anatomical modules persist as a stable substrate for future learning.
For AI, the payoffs are concrete. Anatomically modular networks are far more interpretable: you can literally point to a region and say “this part handles task X.” That matters for mechanistic interpretability, the effort to reverse-engineer how neural networks actually implement their computations. The same spatial structure feeds directly into neuromorphic computing, where hardware efficiency depends on co-locating neurons and their connections. BIMT could work as a training recipe for networks that map cleanly onto neuromorphic chips.
Open questions remain. The current experiments use relatively small networks on stylized tasks. Whether BIMT scales to modern deep learning architectures, and whether spatial organization stays interpretable at that scale, is unknown. The neuron-swapping mechanism adds training complexity, and efficient implementations will matter for broader adoption.
The spatial organization of biological brains isn’t a biological accident. BIMT suggests it reflects a computational principle: networks that respect physical locality become more organized, more efficient, and easier to interpret.
IAIFI Research Highlights
This paper bridges computational neuroscience and machine learning, using a neuroscience-inspired training algorithm to reproduce a core organizational feature of biological brains in artificial networks.
BIMT achieves a better performance-sparsity tradeoff than standard regularization while producing anatomically organized networks that are more interpretable and better suited for neuromorphic hardware.
A minimal computational model shows that spatial wiring costs alone can drive the emergence of anatomical modularity, offering a mechanistic account of brain organization without requiring complex biological detail.
Future work will test whether BIMT scales to larger architectures and enables continual learning through stable anatomical modules; the paper is available at [arXiv:2310.07711](https://arxiv.org/abs/2310.07711).
Original Paper Details
Growing Brains: Co-emergence of Anatomical and Functional Modularity in Recurrent Neural Networks
2310.07711
Ziming Liu, Mikail Khona, Ila R. Fiete, Max Tegmark
Recurrent neural networks (RNNs) trained on compositional tasks can exhibit functional modularity, in which neurons can be clustered by activity similarity and participation in shared computational subtasks. Unlike brains, these RNNs do not exhibit anatomical modularity, in which functional clustering is correlated with strong recurrent coupling and spatial localization of functional clusters. Contrasting with functional modularity, which can be ephemerally dependent on the input, anatomically modular networks form a robust substrate for solving the same subtasks in the future. To examine whether it is possible to grow brain-like anatomical modularity, we apply a recent machine learning method, brain-inspired modular training (BIMT), to a network being trained to solve a set of compositional cognitive tasks. We find that functional and anatomical clustering emerge together, such that functionally similar neurons also become spatially localized and interconnected. Moreover, compared to standard $L_1$ or no regularization settings, the model exhibits superior performance by optimally balancing task performance and network sparsity. In addition to achieving brain-like organization in RNNs, our findings also suggest that BIMT holds promise for applications in neuromorphic computing and enhancing the interpretability of neural network architectures.