
Grokking as Compression: A Nonlinear Complexity Perspective
Authors
Ziming Liu, Ziqian Zhong, Max Tegmark
Abstract
We attribute grokking, the phenomenon where generalization is much delayed after memorization, to compression. To do so, we define linear mapping number (LMN) to measure network complexity, which is a generalized version of linear region number for ReLU networks. LMN can nicely characterize neural network compression before generalization. Although the $L_2$ norm has been a popular choice for characterizing model complexity, we argue in favor of LMN for a number of reasons: (1) LMN can be naturally interpreted as information/computation, while $L_2$ cannot. (2) In the compression phase, LMN has linear relations with test losses, while $L_2$ is correlated with test losses in a complicated nonlinear way. (3) LMN also reveals an intriguing phenomenon of the XOR network switching between two generalization solutions, while $L_2$ does not. Besides explaining grokking, we argue that LMN is a promising candidate as the neural network version of the Kolmogorov complexity since it explicitly considers local or conditioned linear computations aligned with the nature of modern artificial neural networks.
Concepts
The Big Picture
Imagine teaching a child long division. For weeks, they memorize dozens of example problems by rote, matching inputs to outputs without grasping the underlying rule. Then one day, something clicks: they don’t just know the answers; they understand division.
That delayed moment of insight is what researchers call grokking in neural networks. A network trains on a small dataset and quickly achieves perfect accuracy on training examples, but fails completely on new data. Training continues. Nothing seems to happen. Thousands of steps later, the network suddenly generalizes, getting the right answer on examples it has never seen.
What was it doing during all that seemingly wasted time?
A paper from MIT and IAIFI researchers Ziming Liu, Ziqian Zhong, and Max Tegmark proposes an answer: the network was compressing. To make that case, they introduced a new way to measure how complicated a neural network actually is, one based on what the network computes rather than what its parameters look like.
Key Insight: Grokking happens because neural networks first find a complex, bloated memorization solution, then slowly compress toward a simpler generalization solution. A new metric called the Linear Mapping Number (LMN) tracks this compression precisely.
How It Works
The standard tool for measuring neural network complexity has been the L2 norm: the sum of squared connection weights. Smaller weights, the thinking goes, mean a simpler model.
The MIT team argues this is a poor proxy. A deep network can have enormous weights while computing only a single simple function. What matters isn’t how large the numbers are; it’s how many distinct computations the network performs.
Their alternative, the Linear Mapping Number (LMN), builds on a geometric insight. A ReLU network doesn’t compute one smooth function. It carves up the space of possible inputs into regions, behaving like a completely different linear function within each one. Think of it like origami: you fold a flat sheet repeatedly and end up with a complex 3D shape. The number of flat facets is the number of linear regions, and that’s a direct measure of complexity.
LMN generalizes this idea to networks with any activation function, not just ReLU. Pick two input samples and draw a straight line between them, then watch what happens to that line after it passes through the network. If it stays straight, both samples are processed by the same internal rule. If it curves, they’re not.
The team defines a linear connectivity matrix L, where each entry L_ij captures how “straight” the path between samples i and j remains. They compute the eigenvalue spectrum of L, treat it as a probability distribution, and apply Von Neumann entropy (from quantum information theory) to count how many effectively distinct linear mappings the matrix encodes. That count is the LMN.
In practice, three steps:
- For each pair of input samples, interpolate a path in input space and measure how curved the output path is (via R² of linear regression).
- Stack all pairwise measurements into the N×N matrix L.
- Compute the eigenvalue spectrum of L, treat it as a probability distribution, and exponentiate the entropy to get LMN.
Why It Matters
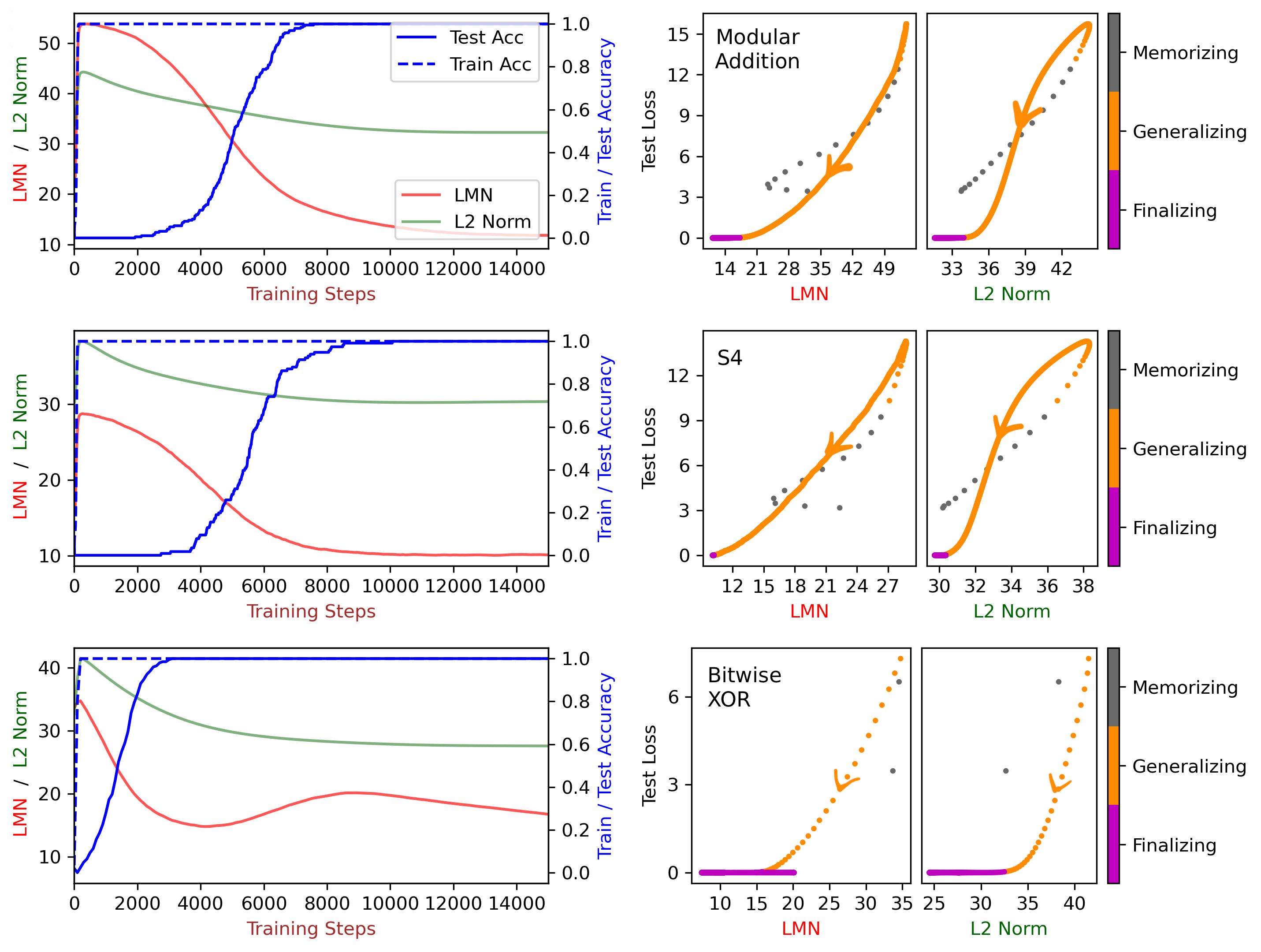
The researchers tested LMN on three algorithmic tasks where grokking is known to occur: modular addition (clock arithmetic), the permutation group S5 (symmetry operations on five elements), and multi-digit XOR.
During the gap between memorization and generalization, LMN drops steadily and tracks test loss in a clean linear relationship. The network is becoming simpler, computation by computation, as it discovers the underlying rule. L2 norm correlates with test loss too, but in a messy, nonlinear way.
The XOR experiment turned up something unexpected. After grokking, instead of leveling off, LMN showed a double-descent: dropping, rising, then dropping again. XOR admits two different generalization algorithms of nearly equal efficiency, and the network oscillates between them. LMN made this invisible phenomenon visible. L2 norm showed nothing.
The authors also argue that LMN is a candidate for a neural network analogue of Kolmogorov complexity, the theoretical minimum description length of a computational object. Kolmogorov complexity is uncomputable in general. LMN offers a practical approximation: it counts how many distinct linear computations a network actually uses, which fits naturally with how piecewise-linear networks work.
There is a broader connection to physics here. Tegmark and collaborators have long argued that the universe’s laws are compressible, that deep regularities exist waiting to be discovered. A metric that captures how efficiently a network compresses what it has learned touches on the same questions physicists ask about nature and information. If grokking really is compression, measuring it quantitatively gets us closer to understanding why neural networks generalize at all.
Bottom Line: LMN is the first complexity metric that tracks neural network generalization cleanly and linearly, showing that grokking is compression and pointing toward a practical, physically interpretable version of Kolmogorov complexity for modern AI.
IAIFI Research Highlights
This work applies Von Neumann entropy, a concept from quantum information theory, to quantify neural network complexity. It's exactly the kind of cross-pollination between physics and AI that defines IAIFI's mission.
LMN outperforms the widely used L2 norm for tracking generalization dynamics. It also gives researchers an interpretable complexity measure they could use for regularization and model selection.
Connecting neural network compression to Kolmogorov complexity reframes learning as information compression, linking machine intelligence to foundational questions in information theory and physics.
Future work may extend LMN to larger transformer architectures and use it as a training signal for improving generalization. The paper is available as [arXiv:2310.05918](https://arxiv.org/abs/2310.05918).
Original Paper Details
Grokking as Compression: A Nonlinear Complexity Perspective
[2310.05918](https://arxiv.org/abs/2310.05918)
Ziming Liu, Ziqian Zhong, Max Tegmark
We attribute grokking, the phenomenon where generalization is much delayed after memorization, to compression. To do so, we define linear mapping number (LMN) to measure network complexity, which is a generalized version of linear region number for ReLU networks. LMN can nicely characterize neural network compression before generalization. Although the $L_2$ norm has been a popular choice for characterizing model complexity, we argue in favor of LMN for a number of reasons: (1) LMN can be naturally interpreted as information/computation, while $L_2$ cannot. (2) In the compression phase, LMN has linear relations with test losses, while $L_2$ is correlated with test losses in a complicated nonlinear way. (3) LMN also reveals an intriguing phenomenon of the XOR network switching between two generalization solutions, while $L_2$ does not. Besides explaining grokking, we argue that LMN is a promising candidate as the neural network version of the Kolmogorov complexity since it explicitly considers local or conditioned linear computations aligned with the nature of modern artificial neural networks.