
GenEFT: Understanding Statics and Dynamics of Model Generalization via Effective Theory
Authors
David D. Baek, Ziming Liu, Max Tegmark
Abstract
We present GenEFT: an effective theory framework for shedding light on the statics and dynamics of neural network generalization, and illustrate it with graph learning examples. We first investigate the generalization phase transition as data size increases, comparing experimental results with information-theory-based approximations. We find generalization in a Goldilocks zone where the decoder is neither too weak nor too powerful. We then introduce an effective theory for the dynamics of representation learning, where latent-space representations are modeled as interacting particles (repons), and find that it explains our experimentally observed phase transition between generalization and overfitting as encoder and decoder learning rates are scanned. This highlights the power of physics-inspired effective theories for bridging the gap between theoretical predictions and practice in machine learning.
Concepts
The Big Picture
Imagine you’re training a dog. Too few examples of “sit,” and the dog stays confused. Too many repetitions in one spot, and it only performs in the living room, not the park. Somewhere in between lies the sweet spot where genuine understanding clicks. Neural networks face the same puzzle, and finding that sweet spot has always required expensive trial-and-error.
Generalization, a model’s ability to apply what it learned from training data to brand-new inputs, is fragile. Tweak the learning rate (how fast a model adjusts itself during training), change the dataset size, or alter the architecture, and you can tip from elegant generalization into useless memorization. Theorists have written bounds describing when generalization should work, but these rarely give practitioners concrete numbers: how much data do I need? What learning rate should I use?
A team at MIT (David Baek, Ziming Liu, and Max Tegmark) attacked the problem with physics. Their framework, GenEFT, borrows a physicist’s favorite trick: building a stripped-down model that captures essential behavior without tracking every microscopic detail, the same way weather forecasters predict rain without simulating every air molecule. The result is a theory that predicts when and why neural networks generalize.
GenEFT predicts the critical amount of training data and the optimal learning rate range for generalization, not from expensive sweeps, but from the structure of the problem itself.
How It Works
GenEFT splits the generalization problem into two angles: statics (what the final trained model looks like, as a function of data) and dynamics (how the model evolves during training, as a function of learning rates).
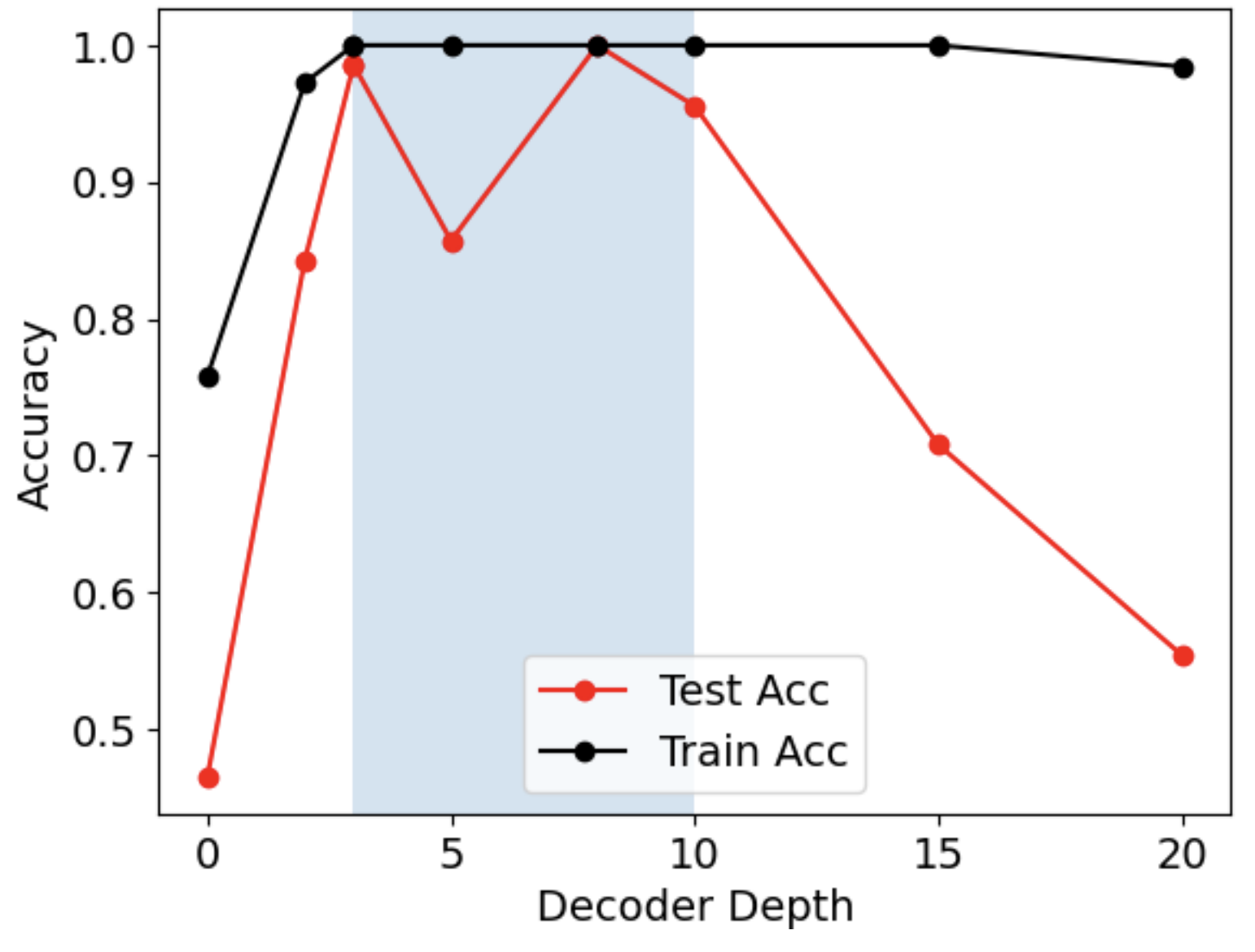
The researchers test everything on knowledge graph learning, teaching a neural network to predict relationships between entities like “greater-than” or “equal modulo 5.” The network has two parts: an encoder that builds a compact internal representation of each entity, and a decoder that reads those representations to make predictions. This clean, controlled setting lets you vary data size and learning rates systematically and watch exactly when generalization kicks in or collapses.
The statics side draws on information theory. Full generalization only becomes possible once the model has seen at least b = log₂(N) training examples, where N is the number of possible graphs. That’s the minimum bits needed to identify which graph you’re dealing with. But it’s only the floor.
In practice, there’s an additional induction gap: extra data needed to learn the structural patterns in the problem (graph symmetries and equivalence classes, the ways some entities are interchangeable or follow repeating rules) that enable true generalization. Correlated data makes things worse because redundant examples carry less new information. The information-theoretic approximation matches experimental curves of test accuracy vs. training fraction closely, capturing the sharp transition from chance-level performance to near-perfect generalization.
The dynamics side introduces Interacting Repon Theory. “Repons” (a blend of “representation” with a nod to particles in physics) are the internal numeric coordinates assigned to each entity in the knowledge graph. Each repon is treated as a particle: similar entities attract, dissimilar ones repel. Learning becomes a problem of tracking how this system of interacting particles moves and settles.
- The encoder updates repon positions, adjusting each entity’s internal coordinates
- The decoder updates its weights to interpret those positions and make correct predictions
- When encoder and decoder learning rates are mismatched, the system destabilizes
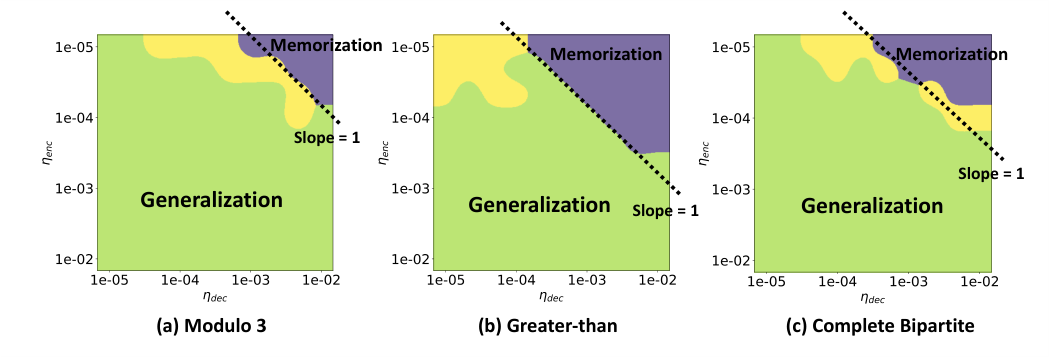
By solving the equations of motion for this particle system, the team derives a phase diagram: a map in the space of encoder vs. decoder learning rates showing which combinations lead to generalization and which lead to failure.
Too fast an encoder relative to the decoder, and representations shift before the decoder can learn to read them. Too strong a decoder, and it memorizes idiosyncratic patterns rather than learning underlying structure. Generalization lives in a Goldilocks zone where learning rates are balanced within a predictable range.
The theoretical phase boundaries match experimental results without curve-fitting. They come directly from the physics of repon interactions.
Why It Matters
Physicists have always built effective theories: simplified models that capture what matters without tracking every degree of freedom. Thermodynamics doesn’t simulate individual molecules. Fluid dynamics skips quantum field theory entirely.
GenEFT applies the same philosophy to machine learning. In practice, instead of running hundreds of hyperparameter sweeps, you get a principled starting point from the problem’s own structure. On the theory side, the repon framework reframes representation learning dynamics using tools from condensed matter physics, where interacting particle systems are already well understood.
Plenty of questions are still open. Whether repon theory can extend to transformers, diffusion models, or reinforcement learning is the big one. Computing the induction gap for real-world datasets like ImageNet or protein sequences would be another major step. And it’s not yet clear whether the Goldilocks zone has analogs in other learning paradigms.
GenEFT casts neural network generalization in the language of physics, predicting critical data thresholds and learning rate phase boundaries from first principles. It’s a rare case where theory actually tells practitioners what to do before they run the experiment.
IAIFI Research Highlights
GenEFT directly imports effective field theory into machine learning, treating representation learning as an interacting particle system. The approach goes beyond analogy to produce quantitative, testable predictions.
The framework provides closed-form estimates for critical training data size and optimal learning rate ranges, giving practitioners theory-grounded guidance rather than requiring brute-force hyperparameter search.
Interacting Repon Theory maps neural network training dynamics onto many-body physics. Phase transitions and collective behavior in physical systems have direct machine learning counterparts.
Future work could extend repon theory to large-scale architectures and real-world datasets, tying diverse generalization phenomena to a single physical framework. The paper is available at [arXiv:2402.05916](https://arxiv.org/abs/2402.05916).
Original Paper Details
GenEFT: Understanding Statics and Dynamics of Model Generalization via Effective Theory
2402.05916
David D. Baek, Ziming Liu, Max Tegmark
We present GenEFT: an effective theory framework for shedding light on the statics and dynamics of neural network generalization, and illustrate it with graph learning examples. We first investigate the generalization phase transition as data size increases, comparing experimental results with information-theory-based approximations. We find generalization in a Goldilocks zone where the decoder is neither too weak nor too powerful. We then introduce an effective theory for the dynamics of representation learning, where latent-space representations are modeled as interacting particles (repons), and find that it explains our experimentally observed phase transition between generalization and overfitting as encoder and decoder learning rates are scanned. This highlights the power of physics-inspired effective theories for bridging the gap between theoretical predictions and practice in machine learning.