
Explicit or Implicit? Encoding Physics at the Precision Frontier
Authors
Victor Breso-Pla, Kevin Greif, Vinicius Mikuni, Benjamin Nachman, Tilman Plehn, Tanvi Wamorkar, Daniel Whiteson
Abstract
High-performance machine learning tools in particle physics rest on two complementary directions: encoding symmetries explicitly in the architecture, and implicitly learning the structure of the data through large-scale (pre-) training. We compare the performance of the representative L-GATr and OmniLearn models on three especially challenging tasks: reweighting-based unfolding, likelihood-ratio estimation, and weakly supervised anomaly detection. Across all benchmarks, both methods achieve comparable performance given the statistical precision of the finetuning datasets, suggesting that the significant efficiency gains from encoding known particle physics structures are largely method-independent.
Concepts
The Big Picture
Imagine teaching a child to recognize dogs. One approach: drill the rules — four legs, fur, tail, barks. Another: show them ten thousand photos and let them figure it out. Both kids end up doing fine. Now scale that question to the most precise experiments ever built, and you have one of particle physics’ most heated debates.
At the Large Hadron Collider, protons smash together at nearly the speed of light millions of times per second. The resulting particle sprays, called jets, carry signatures of exotic physics buried beneath a torrent of noise. Machine learning has become essential for extracting those signals, but physicists disagree about how to build these models.
Should you hard-wire known physics rules directly into a neural network’s design? Rules like the fact that a collision looks identical whether you’re standing still or racing past at constant speed? Or should you train a massive model on enormous amounts of data and let it absorb the physics itself?
A new study from researchers at Harvard, Stanford, UC Irvine, and Heidelberg puts these two philosophies head-to-head on the hardest tasks in precision collider physics. The answer turns out to be surprisingly clean.
Key Insight: When both approaches have access to the same fine-tuning data, encoding physics rules explicitly and learning them from massive datasets deliver essentially identical performance, suggesting both strategies are viable at the precision frontier.
How It Works
The researchers pitted two state-of-the-art models against each other. L-GATr (Lorentz Geometric Algebra Transformer) takes the explicit approach: it uses geometric algebra to hard-wire the rules of special relativity into every network layer. Each particle is encoded as a multivector, an object that packages energy, momentum, and orientation in a form that stays consistent under any rotation or change of reference frame. L-GATr literally cannot violate the laws of special relativity.
OmniLearn takes the opposite path. It’s a foundation model for particle physics (think GPT for collider data) that learns physics implicitly by pretraining on a massive, diverse collection of simulated collider events. No built-in symmetry constraints. It absorbs the rules from data, the way a child absorbs grammar by hearing enough sentences.
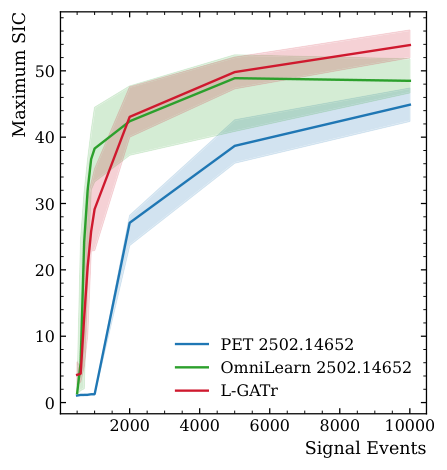
The team tested both models on three precision benchmark tasks, each demanding subtle, near-identical class separation:
- Reweighting-based unfolding for proton-proton (pp) collisions: correcting simulation artifacts to recover the true physics distribution, where signal and background look nearly identical.
- Likelihood-ratio estimation for electron-proton (ep) collisions: quantifying how much more or less likely a dataset is under one physical theory versus another, comparing distributions that differ only by finely tuned parameters.
- Weakly supervised anomaly detection: hunting for new physics using only indirect, approximate labels, where almost all events are standard-model background with only a handful of genuine anomalies.
These aren’t easy classification problems. They’re precision tasks where differences between signal and background are measured in fractions of a percent. Earlier benchmarks like top-quark tagging, where the two classes look very different, had already shown that explicitly encoding symmetry (equivariance) helps, though less so as model capacity grows. The authors pushed deliberately into the regime where the distinction might actually matter.
The results are consistent across all three benchmarks. L-GATr and OmniLearn perform comparably within statistical uncertainties. Neither model dominates.
When the fine-tuning dataset is small, both struggle equally. When it grows, both improve equally. Architectural philosophy turns out to be secondary to how much labeled fine-tuning data you provide.
One practical difference is that L-GATr can be more computationally efficient because it doesn’t need to learn what it already knows. OmniLearn compensates with scale: massive pretraining amortizes the cost of learning physics from scratch. Different trails, same mountaintop.
Why It Matters
This paper arrives at a pivotal moment for AI in fundamental physics. The field has been investing heavily in two parallel infrastructures: specialized equivariant architectures on one side, large collider foundation models on the other. Knowing these approaches converge at the precision frontier isn’t a disappointment. It’s a roadmap.
Teams can now choose based on practical constraints (available compute, data volume, deployment context) rather than worrying that one philosophy is fundamentally superior.
The deeper implication is about where to push next. If both methods plateau at the same performance ceiling, that ceiling is set by the statistical precision of fine-tuning data, not by architectural choices. The next breakthrough won’t come from fancier symmetry groups or bigger transformers alone. It will likely require rethinking how training data is curated, how simulation uncertainties are handled, and how models are evaluated on physics-relevant metrics beyond raw classification accuracy.
As the LHC accumulates more data, an open question remains: does this convergence hold in the ultra-high-statistics regime, or does one approach eventually pull ahead?
Bottom Line: Whether you encode particle physics the hard way or learn it from data, the performance ceiling at the precision frontier is the same. It’s set by how much fine-tuning data you have, not by your architectural philosophy.
IAIFI Research Highlights
This work connects geometric deep learning with precision experimental particle physics, applying equivariant architectures and foundation model pretraining directly to core challenges in LHC data analysis.
The study provides empirical evidence that explicit symmetry encoding and large-scale implicit pretraining converge to equivalent performance on fine-grained discrimination tasks, with direct implications for how AI systems should be designed for structured physical domains.
By benchmarking ML tools on unfolding, likelihood-ratio estimation, and anomaly detection (three pillars of the precision collider physics program) the work confirms that modern AI methods are ready for deployment in the search for physics beyond the Standard Model.
Future work should probe whether this convergence holds in the ultra-high-statistics regime as LHC datasets grow, and explore hybrid architectures that combine explicit symmetry priors with large-scale pretraining; the full study is available at [arXiv:2603.08802](https://arxiv.org/abs/2603.08802).
Original Paper Details
Explicit or Implicit? Encoding Physics at the Precision Frontier
2603.08802
Victor Breso-Pla, Kevin Greif, Vinicius Mikuni, Benjamin Nachman, Tilman Plehn, Tanvi Wamorkar, Daniel Whiteson
High-performance machine learning tools in particle physics rest on two complementary directions: encoding symmetries explicitly in the architecture, and implicitly learning the structure of the data through large-scale (pre-) training. We compare the performance of the representative L-GATr and OmniLearn models on three especially challenging tasks: reweighting-based unfolding, likelihood-ratio estimation, and weakly supervised anomaly detection. Across all benchmarks, both methods achieve comparable performance given the statistical precision of the finetuning datasets, suggesting that the significant efficiency gains from encoding known particle physics structures are largely method-independent.