
Enhancing searches for resonances with machine learning and moment decomposition
Authors
Ouail Kitouni, Benjamin Nachman, Constantin Weisser, Mike Williams
Abstract
A key challenge in searches for resonant new physics is that classifiers trained to enhance potential signals must not induce localized structures. Such structures could result in a false signal when the background is estimated from data using sideband methods. A variety of techniques have been developed to construct classifiers which are independent from the resonant feature (often a mass). Such strategies are sufficient to avoid localized structures, but are not necessary. We develop a new set of tools using a novel moment loss function (Moment Decomposition or MoDe) which relax the assumption of independence without creating structures in the background. By allowing classifiers to be more flexible, we enhance the sensitivity to new physics without compromising the fidelity of the background estimation.
Concepts
The Big Picture
Imagine you’re searching for a needle in a haystack, but the haystack itself is constantly shifting. Now imagine you train a powerful AI to spot needles, only to discover the AI has accidentally bent some straw into needle shapes. That’s roughly the problem facing physicists hunting for new particles at the world’s most powerful colliders.
The technique is called bump hunting: physicists look for unexpected spikes in a smooth spectrum of energy and mass. When a new particle exists, the lighter particles it decays into pile up at a characteristic energy, creating a visible spike above the otherwise smooth background. It’s how the Higgs boson was discovered, and the method dates back to the ρ meson in the 1960s. Today, bump hunts scan energies into the multi-TeV range, territory accessible only at massive accelerators like the LHC.
The trouble begins when physicists sharpen their searches using ML classifiers. A well-trained neural network may learn that certain collision features correlate with the total mass-energy of the event. Apply a score cutoff, and suddenly the background, which should be featureless, develops an artificial spike. A fake signal. A ghost.
Researchers from MIT and Lawrence Berkeley National Laboratory developed a framework called Moment Decomposition (MoDe) that sidesteps this problem, achieving higher sensitivity to new physics without corrupting the background estimate.
Key Insight: You don’t need a classifier to be completely independent of mass to avoid fake bumps. You just need it to avoid creating localized structures. MoDe exploits this looser requirement to build classifiers that are both more powerful and safe.
How It Works
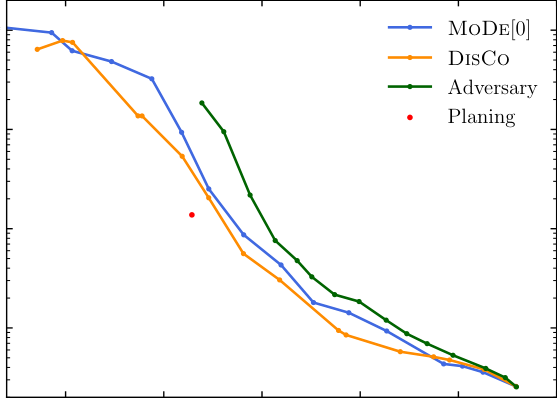
The standard fix to bump-sculpting has been decorrelation: forcing the classifier to be statistically independent of mass so it cannot use any mass information when deciding whether an event looks like a signal. Techniques like Distance Correlation (DisCo), adversarial networks, and planing all penalize mass correlations. They work, but they overpay.
By demanding complete independence, decorrelation handicaps the classifier. It cannot exploit any mass-related information, even information that would boost signal sensitivity without causing sculpting.
MoDe starts from a different premise: this restriction is too strong. A classifier with a perfectly linear dependence on mass creates a sloped background after selection, but no localized bump. A bump hunt cares about bumps, not slopes. The researchers formalized this with a moment loss function, a training penalty that suppresses only the mass-dependent patterns that actually produce sculpting.
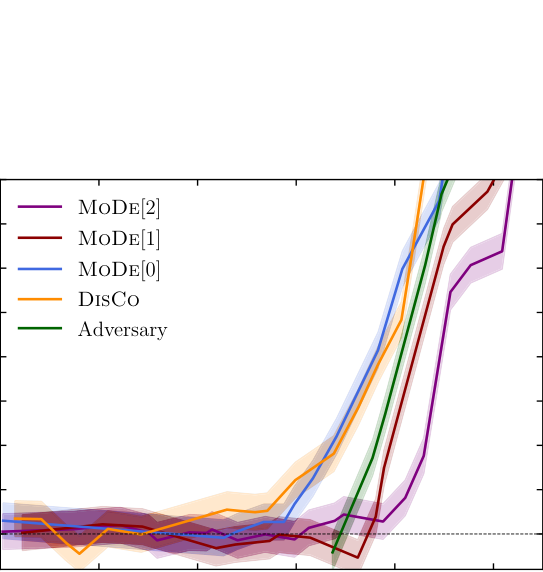
Here’s the machinery. The classifier output is expanded in terms of its Legendre polynomial moments, a set of basis functions that decompose a distribution into constant, linear, quadratic, and higher-order components. Think of it as breaking a complex curve into simple building blocks. The loss function then selectively penalizes only the components that would sculpt the background:
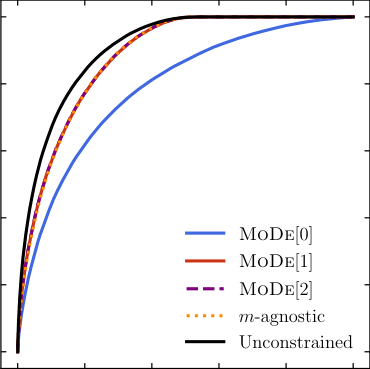
- MoDe-0: penalizes any mass dependence, equivalent to standard decorrelation
- MoDe-1: allows linear mass dependence, penalizes higher moments
- MoDe-2: allows linear and quadratic dependence, even more flexible
Analysts can layer on additional constraints: bound the slope of linear dependence, or restrict quadratic terms to be monotonic. These prevent dangerous background curvature even when the classifier uses mass information.
The team validated MoDe on two test cases. First, a synthetic model designed to cleanly illustrate each method’s behavior. Second, boosted hadronic W tagging, which involves identifying highly energetic W bosons (force carriers of the weak interaction) decaying to quark pairs and distinguishing them from the overwhelming flood of QCD jets. This is the kind of analysis that matters for heavy-resonance searches at the LHC, where both ATLAS and CMS have deployed ML-based W taggers.
In both cases, MoDe-1 and MoDe-2 achieved better signal-to-background discrimination than fully decorrelated methods. Background distributions in the sideband regions (the portions of the mass spectrum away from a potential signal, used to estimate the background shape) remained smooth and usable.
Why It Matters
For years, the implicit assumption in particle physics has been: if decorrelation prevents sculpting, then decorrelation is what we need. MoDe questions that assumption and asks what’s actually required. The answer is a weaker condition, and the gap between “sufficient” and “necessary” is where the extra sensitivity lives.
The payoff goes beyond W tagging. Any bump hunt that combines ML-enhanced selection with sideband background estimation could benefit, from searches for dark matter mediators to heavy resonances and exotic signatures. The moment loss is fully differentiable and plugs into standard training pipelines without modification. It scales to higher-order moments and multi-dimensional protected attributes. Similar ideas appear in domain adaptation and algorithmic fairness, and MoDe’s relaxed-constraint philosophy may prove useful there too.
Bottom Line: MoDe gives particle physicists a sharper tool for new-physics searches by replacing an overly conservative independence requirement with a precisely calibrated tolerance for controlled mass dependence. More flexibility, same safety guarantee.
IAIFI Research Highlights
This work takes modern statistical learning theory (moment decomposition and constrained loss functions) and applies it to one of collider physics' most fundamental search strategies, connecting ML methodology directly to experimental phenomenology.
MoDe introduces a class of differentiable loss functions that enforce structured, bounded dependencies between a classifier and a protected attribute, moving constrained ML past simple independence requirements.
By boosting the sensitivity of bump hunts without degrading background estimation, MoDe extends the discovery reach for new particles and forces at the LHC and future colliders.
Future extensions include higher-order moment constraints, multi-dimensional resonant features, and deployment in ongoing LHC analyses; full details are in [arXiv:2010.09745](https://arxiv.org/abs/2010.09745).