
Dynamic Sparse Training with Structured Sparsity
Authors
Mike Lasby, Anna Golubeva, Utku Evci, Mihai Nica, Yani Ioannou
Abstract
Dynamic Sparse Training (DST) methods achieve state-of-the-art results in sparse neural network training, matching the generalization of dense models while enabling sparse training and inference. Although the resulting models are highly sparse and theoretically less computationally expensive, achieving speedups with unstructured sparsity on real-world hardware is challenging. In this work, we propose a sparse-to-sparse DST method, Structured RigL (SRigL), to learn a variant of fine-grained structured N:M sparsity by imposing a constant fan-in constraint. Using our empirical analysis of existing DST methods at high sparsity, we additionally employ a neuron ablation method which enables SRigL to achieve state-of-the-art sparse-to-sparse structured DST performance on a variety of Neural Network (NN) architectures. Using a 90% sparse linear layer, we demonstrate a real-world acceleration of 3.4x/2.5x on CPU for online inference and 1.7x/13.0x on GPU for inference with a batch size of 256 when compared to equivalent dense/unstructured (CSR) sparse layers, respectively.
Concepts
The Big Picture
Imagine a library where most shelves are empty. You’d think a librarian could find every book quickly with so few to locate. But if the books are scattered randomly, one here, three there, the librarian still has to check every shelf. The library is technically sparse, but searching it takes just as long.
This paradox has dogged neural network compression for years. Researchers have gotten very good at training networks with 90% or more of their weights (the numerical values that determine how a model processes data) set to zero. This is called sparse training. Sparse models should be cheaper to run: fewer calculations, less memory. But “theoretically cheaper” and “actually faster” are two different things.
When zero weights are scattered randomly, real hardware can’t exploit the sparsity. CPUs and GPUs read data in orderly, predictable chunks. The library is mostly empty, but the librarian is still exhausted.
A team from the University of Calgary, MIT, Google DeepMind, and affiliated institutions found a way to have it both ways. Their method, Structured RigL (SRigL), trains neural networks that are both highly sparse and organized in a pattern hardware can actually exploit. On GPU inference, it achieves real-world speedups of up to 13x compared to standard sparse formats.
Key Insight: SRigL makes theoretical efficiency gains real by learning structured sparsity during training rather than imposing it afterward, so the network adapts its weights to a hardware-friendly pattern from the start.
How It Works
SRigL builds on an existing algorithm called RigL (Rigged Lottery), a Dynamic Sparse Training (DST) method. Traditional pruning trains a full network first, then cuts weights. DST does it differently: sparsity is maintained throughout training. Weights are periodically pruned (smallest magnitude) and regrown (largest gradient magnitude), and the network explores different sparse connectivity patterns as it learns. RigL can match or beat dense models at high sparsity. The catch: its sparsity is unstructured, with surviving weights scattered at arbitrary positions.
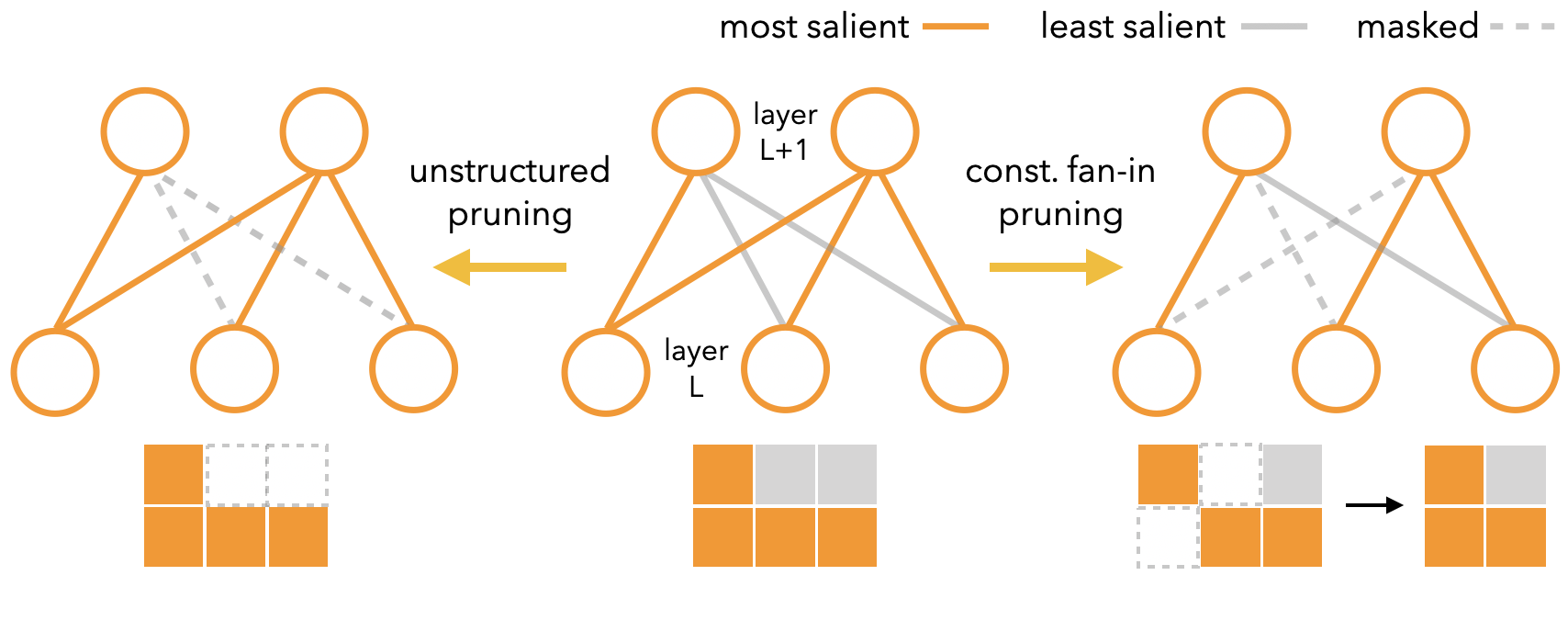
SRigL adds one hard constraint: constant fan-in, meaning every neuron receives exactly the same number of incoming connections. Think of each neuron being allowed exactly 10 input wires, no more, no less. This creates fine-grained N:M sparsity: out of every M consecutive weights in a row, exactly N are nonzero. A GPU no longer has to hunt for random weight positions. It loads weights in predictable, contiguous blocks.
The training procedure runs in three stages:
- Sparse initialization: The network starts with a random sparse mask satisfying constant fan-in.
- Dynamic mask updates: At regular intervals, SRigL drops the smallest-magnitude weights per neuron and grows the largest-gradient-magnitude weights, always preserving fan-in.
- Neuron ablation: Above ~90% sparsity, standard RigL naturally kills entire neurons by zeroing all their incoming weights. SRigL makes this explicit, letting active neurons concentrate their fixed fan-in budget on the most useful connections.
That third stage came from careful empirical analysis. At extreme sparsity, RigL was already doing neuron ablation, but implicitly and inefficiently. Making it explicit lets the algorithm lean into the behavior, and performance at extreme sparsity improved markedly.
There’s a theoretical payoff too. The paper shows that constant fan-in layers have lower variance in their output norms compared to equally sparse but unstructured layers. Internal signals stay better-behaved during training, which translates to more stable optimization.
Why It Matters
Algorithmic efficiency and real-world efficiency have been frustratingly disconnected in the compression community. Papers routinely report reductions in FLOPs (the basic arithmetic a model performs) that never translate to faster inference on actual hardware.
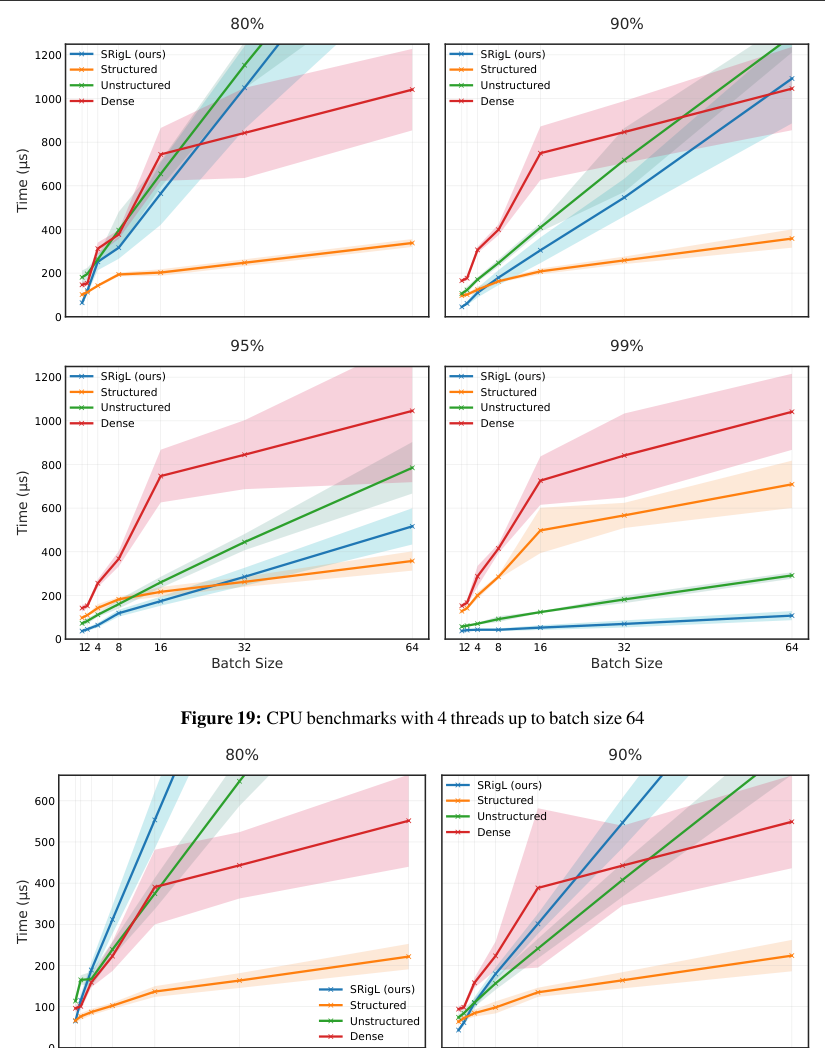
SRigL attacks this gap head-on. On a 90% sparse linear layer, it achieves 3.4x speedup over dense and 2.5x over unstructured sparse on CPU for single-sample inference. On GPU with batch size 256, the gains are sharper: 1.7x over dense and 13.0x over unstructured sparse. These are wall-clock measurements, not theoretical FLOP counts.
As models get larger and more expensive to deploy, techniques that make inference genuinely faster carry real weight. This is especially true in scientific applications like physics simulations, particle detector readouts, and gravitational wave analysis, where models must run at high throughput on constrained hardware. Unstructured pruning never delivered on that promise; structured sparsity without accuracy loss might.
The authors evaluate SRigL primarily on image classification, so how constant fan-in transfers to transformers, diffusion models, or graph neural networks remains open. The neuron ablation behavior at extreme sparsity also raises questions about what the surviving network topology looks like, a thread worth pulling from an interpretability angle.
Bottom Line: SRigL shows that structured sparsity doesn’t require sacrificing accuracy. By learning structure and weights simultaneously, it delivers hardware-ready sparse networks with up to 13x real-world inference speedup over unstructured sparse formats.
IAIFI Research Highlights
The work connects fundamental neural network theory (why constant fan-in reduces output-norm variance) with practical hardware engineering. This is the kind of cross-cutting question IAIFI was built to tackle.
SRigL raises the bar for structured dynamic sparse training, showing that hardware-friendly sparsity patterns can be learned end-to-end without the accuracy penalty that structured pruning has traditionally carried.
Efficient sparse inference matters directly for physics experiments that need real-time AI on edge hardware, from trigger systems in particle detectors to fast gravitational wave classifiers where latency counts.
Future work will likely extend constant fan-in structured sparsity to transformer architectures and investigate connections between neuron ablation and network topology. The paper ([arXiv:2305.02299](https://arxiv.org/abs/2305.02299)) appeared at ICLR 2024.
Original Paper Details
Dynamic Sparse Training with Structured Sparsity
2305.02299
Mike Lasby, Anna Golubeva, Utku Evci, Mihai Nica, Yani Ioannou
Dynamic Sparse Training (DST) methods achieve state-of-the-art results in sparse neural network training, matching the generalization of dense models while enabling sparse training and inference. Although the resulting models are highly sparse and theoretically less computationally expensive, achieving speedups with unstructured sparsity on real-world hardware is challenging. In this work, we propose a sparse-to-sparse DST method, Structured RigL (SRigL), to learn a variant of fine-grained structured N:M sparsity by imposing a constant fan-in constraint. Using our empirical analysis of existing DST methods at high sparsity, we additionally employ a neuron ablation method which enables SRigL to achieve state-of-the-art sparse-to-sparse structured DST performance on a variety of Neural Network (NN) architectures. Using a 90% sparse linear layer, we demonstrate a real-world acceleration of 3.4x/2.5x on CPU for online inference and 1.7x/13.0x on GPU for inference with a batch size of 256 when compared to equivalent dense/unstructured (CSR) sparse layers, respectively.