
Deep learning: a statistical viewpoint
Authors
Peter L. Bartlett, Andrea Montanari, Alexander Rakhlin
Abstract
The remarkable practical success of deep learning has revealed some major surprises from a theoretical perspective. In particular, simple gradient methods easily find near-optimal solutions to non-convex optimization problems, and despite giving a near-perfect fit to training data without any explicit effort to control model complexity, these methods exhibit excellent predictive accuracy. We conjecture that specific principles underlie these phenomena: that overparametrization allows gradient methods to find interpolating solutions, that these methods implicitly impose regularization, and that overparametrization leads to benign overfitting. We survey recent theoretical progress that provides examples illustrating these principles in simpler settings. We first review classical uniform convergence results and why they fall short of explaining aspects of the behavior of deep learning methods. We give examples of implicit regularization in simple settings, where gradient methods lead to minimal norm functions that perfectly fit the training data. Then we review prediction methods that exhibit benign overfitting, focusing on regression problems with quadratic loss. For these methods, we can decompose the prediction rule into a simple component that is useful for prediction and a spiky component that is useful for overfitting but, in a favorable setting, does not harm prediction accuracy. We focus specifically on the linear regime for neural networks, where the network can be approximated by a linear model. In this regime, we demonstrate the success of gradient flow, and we consider benign overfitting with two-layer networks, giving an exact asymptotic analysis that precisely demonstrates the impact of overparametrization. We conclude by highlighting the key challenges that arise in extending these insights to realistic deep learning settings.
Concepts
The Big Picture
Imagine a student who memorizes every answer in the textbook, typos and errors included, and then aces the final exam on entirely new questions. According to classical statistics, this shouldn’t work. Memorizing noise should destroy generalization. Yet this is almost exactly what modern deep neural networks do, every day, at scale.
They overfit training data perfectly and still make highly accurate predictions.
This paradox has dogged machine learning theory for years. The standard explanation for why statistical models generalize rests on a simple intuition: more complex models have more ways to go wrong, so keep models simple. That framework doesn’t apply to deep learning as practiced. Networks with billions of parameters, trained until they achieve near-zero error on noisy data, shouldn’t generalize. But they do.
In this survey, Peter Bartlett (UC Berkeley), Andrea Montanari (Stanford), and Alexander Rakhlin (MIT) attack the mystery with rigorous statistical tools. They don’t claim to fully solve it, but they identify three principles that begin to explain why deep learning outperforms what theory predicts it should.
Key Insight: Overparametrization, implicit regularization, and benign overfitting are three linked phenomena that explain deep learning’s ability to generalize despite perfectly memorizing noisy training data.
How It Works
The authors start by diagnosing why classical theory fails. The standard toolkit, uniform convergence bounds, gives mathematical guarantees that training error reliably predicts test error, but only when model complexity is controlled. Larger models should have larger “capacity,” which should mean more overfitting. The classical prescription: penalize complexity explicitly, or choose a model just expressive enough to fit the data.
Deep learning violates this at every step. Practitioners train vastly overparametrized models (networks where parameters far outnumber training examples) with no explicit regularization, until training loss hits essentially zero. Uniform convergence bounds for such models are vacuous, implying generalization error above 100%. Useless.
So what actually explains the success? The paper argues for three principles, each illustrated with rigorous analysis in simpler settings:
-
Overparametrization enables optimization. Gradient descent on highly non-convex loss surfaces should get stuck in bad local minima. In practice, it doesn’t. The authors examine the linear regime, where a network behaves approximately like a linear model captured by the Neural Tangent Kernel framework. Here they prove gradient flow converges to a global minimum with precise rates. Overparametrization, far from being a liability, makes the optimization loss landscape more benign.
-
Gradient methods impose implicit regularization. With more parameters than training examples, infinitely many solutions fit the data exactly. Gradient descent doesn’t find just any interpolating solution; it tends to find the one with minimum norm, the “simplest” solution in a precise mathematical sense. This implicit bias toward simplicity comes from the optimization algorithm itself, with no explicit penalty needed. The authors demonstrate this for linear models and kernel methods: gradient flow on squared loss with zero initialization converges to the minimum-norm interpolant.
-
Benign overfitting, or memorizing noise without harm. Any minimum-norm interpolant can be decomposed into a signal component capturing the true underlying relationship and a spiky component fitting the noise. In high dimensions, when data has favorable spectral structure (variation spread across many small, independent directions), the spiky component becomes orthogonal to the directions that matter for prediction. The model memorizes the noise, but that noise lives in directions the predictor never uses.
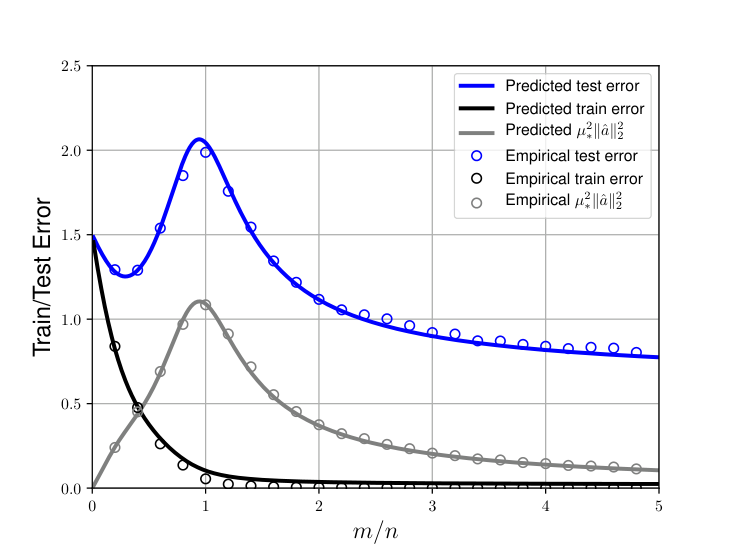
For two-layer networks in the proportional scaling regime, where parameters grow proportionally to training examples, the authors provide an exact asymptotic analysis. They compute precise test error as a function of the overparametrization ratio, and the result is a double descent curve. Error rises as parameters increase (the classical regime), peaks near the interpolation threshold where the model just barely fits all training data, then falls again with further overparametrization. That second descent is the benign overfitting regime.
Why It Matters
These results connect directly to practice. Physics-informed machine learning, scientific discovery pipelines, and AI systems analyzing data from particle colliders or gravitational wave detectors all rely on deep networks trained in exactly these regimes. Understanding why these networks generalize, not merely observing that they do, matters for building reliable scientific tools.
The gap between theory and practice has made it hard to know when neural networks can be trusted, what their failure modes look like, and how to improve them systematically. By pinning down overparametrization, implicit regularization, and benign overfitting as three interlocking mechanisms, Bartlett, Montanari, and Rakhlin give future theory something concrete to build on.
The honest limitation: the linear regime is not where deep learning’s magic truly lives. Gradient descent in a linearized model cannot learn hierarchical representations. It cannot discover that edges compose into shapes that compose into objects. Feature learning, the non-linear, compositional representation learning that makes deep networks actually powerful, remains almost entirely unexplained.
The authors are candid about this. But proving that any aspect of the overparametrization story is mathematically rigorous is real progress. The mystery has moved from “inexplicable” to “partially understood, with clear frontiers.”
Bottom Line: Deep learning generalizes not despite overfitting, but partly because of it. Overparametrization makes optimization tractable, gradient descent quietly regularizes, and memorized noise gets harmlessly buried in high-dimensional directions that don’t affect predictions. All three mechanisms now have rigorous theoretical backing, at least in the linear regime.
IAIFI Research Highlights
This survey puts rigorous statistical theory behind the empirical phenomena at work in AI-driven physics research. Overparametrized models are everywhere in scientific ML, and knowing when and why they generalize matters for scientific inference.
The paper gives mathematically precise characterizations of benign overfitting and implicit regularization in neural networks, including exact asymptotic test error formulas for two-layer networks in the proportional scaling regime.
Reliable generalization theory matters for physics applications from gravitational wave analysis to particle physics classification, where overparametrized networks are deployed on high-dimensional data with limited labeled examples.
Future work must close the gap between linear-regime results and the feature-learning regime that drives deep learning's practical power; the paper is available at [arXiv:2103.09177](https://arxiv.org/abs/2103.09177).
Original Paper Details
Deep learning: a statistical viewpoint
2103.09177
Peter L. Bartlett, Andrea Montanari, Alexander Rakhlin
The remarkable practical success of deep learning has revealed some major surprises from a theoretical perspective. In particular, simple gradient methods easily find near-optimal solutions to non-convex optimization problems, and despite giving a near-perfect fit to training data without any explicit effort to control model complexity, these methods exhibit excellent predictive accuracy. We conjecture that specific principles underlie these phenomena: that overparametrization allows gradient methods to find interpolating solutions, that these methods implicitly impose regularization, and that overparametrization leads to benign overfitting. We survey recent theoretical progress that provides examples illustrating these principles in simpler settings. We first review classical uniform convergence results and why they fall short of explaining aspects of the behavior of deep learning methods. We give examples of implicit regularization in simple settings, where gradient methods lead to minimal norm functions that perfectly fit the training data. Then we review prediction methods that exhibit benign overfitting, focusing on regression problems with quadratic loss. For these methods, we can decompose the prediction rule into a simple component that is useful for prediction and a spiky component that is useful for overfitting but, in a favorable setting, does not harm prediction accuracy. We focus specifically on the linear regime for neural networks, where the network can be approximated by a linear model. In this regime, we demonstrate the success of gradient flow, and we consider benign overfitting with two-layer networks, giving an exact asymptotic analysis that precisely demonstrates the impact of overparametrization. We conclude by highlighting the key challenges that arise in extending these insights to realistic deep learning settings.