
Bias and Priors in Machine Learning Calibrations for High Energy Physics
Authors
Rikab Gambhir, Benjamin Nachman, Jesse Thaler
Abstract
Machine learning offers an exciting opportunity to improve the calibration of nearly all reconstructed objects in high-energy physics detectors. However, machine learning approaches often depend on the spectra of examples used during training, an issue known as prior dependence. This is an undesirable property of a calibration, which needs to be applicable in a variety of environments. The purpose of this paper is to explicitly highlight the prior dependence of some machine learning-based calibration strategies. We demonstrate how some recent proposals for both simulation-based and data-based calibrations inherit properties of the sample used for training, which can result in biases for downstream analyses. In the case of simulation-based calibration, we argue that our recently proposed Gaussian Ansatz approach can avoid some of the pitfalls of prior dependence, whereas prior-independent data-based calibration remains an open problem.
Concepts
The Big Picture
Imagine you’re trying to calibrate a thermometer, but every time you use it in a new environment, it gives slightly wrong readings. Not because it’s broken, but because your calibration assumed a fixed temperature range. Deploy it somewhere hotter or colder, and you’re off. Now imagine that thermometer costs a billion dollars and lives inside the Large Hadron Collider.
That’s the challenge facing physicists who use machine learning to calibrate detectors at the LHC. Calibration ensures measurements are “correct on average,” so that when you measure the energy of a jet (a narrow cone of particles spraying from a proton collision), you’re getting the true energy, not a detector artifact.
Machine learning has shown real promise here. But a new paper from MIT’s Jesse Thaler, Rikab Gambhir, and Lawrence Berkeley’s Benjamin Nachman identifies a hidden flaw in many ML calibration methods, one that could corrupt the very physics these tools are meant to protect.
The problem is prior dependence: ML models silently absorb assumptions baked into their training data, and this can bias calibrations in ways that aren’t obvious until something goes wrong. The authors argue for a specific approach that sidesteps this trap for one class of calibrations, while honestly flagging the other class as a genuinely unsolved problem.
A machine learning calibration trained on one distribution of particle energies will give subtly wrong answers when applied to a different distribution, and collecting more data won’t fix it.
How It Works
Particles collide, detectors record the resulting spray, and physicists infer what actually happened. The gap between what the detector records (detector-level features) and the underlying truth (truth-level features, like actual jet energy) has to be closed by calibration. Get it wrong, and every downstream measurement inherits that error, from Higgs boson properties to new-particle searches.
Two flavors of calibration are at play:
- Simulation-based calibration trains on (detector measurement, true value) pairs from detailed physics simulations, learning to map one to the other.
- Data-based calibration takes a different approach: it adjusts simulated distributions to match real experimental data, correcting for imperfections in the simulation itself.
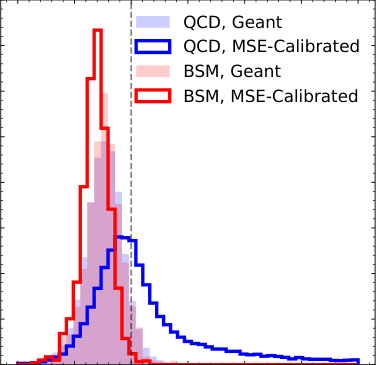
For simulation-based calibration, the standard approach trains a neural network to minimize mean squared error (MSE), which pushes the model toward predicting the conditional average true value for each detector measurement. The catch: that average depends on the training distribution.
The model learns E[truth | detector measurement] averaged over the training sample. Apply it to a different distribution and the conditional average shifts, even if the detector’s physical response hasn’t changed at all.
The paper shows this with explicit Gaussian examples. A calibration derived from jets peaking at 100 GeV gives wrong answers on jets peaking at 200 GeV, even when the detector behaves identically at both energies. The bias is baked in.
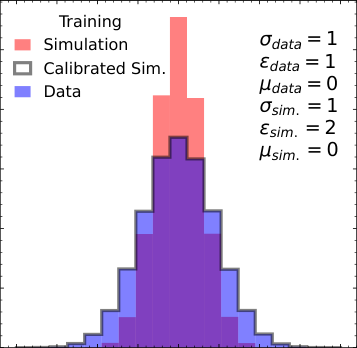
So does their Gaussian Ansatz approach do better? Rather than learning a single average, this method models the full shape of the detector response, fitting it to a Gaussian and extracting parameters directly. Because it captures the response shape rather than a sample-averaged statistic, it achieves prior independence: the calibration works regardless of the true-energy distribution you feed it. The short answer is yes, though with caveats.
The situation for data-based calibration is grimmer. Here the goal is to learn reweighting functions that upweight or downweight simulated events until the simulation matches real data. Recent ML proposals learn these weights from a specific event sample, but the weights break down on events drawn from different underlying distributions. The same root cause is at work. No prior-independent data-based calibration method exists yet.
The authors ground these findings in a concrete jet energy study using simulated LHC data: train on one energy distribution, test on another. The biases show up clearly and are quantifiable. The Gaussian Ansatz substantially outperforms naive MSE-based calibration in the simulation-based case. Data-based approaches show persistent prior-induced bias regardless of the ML method used.
Why It Matters
Calibration is the invisible foundation of every measurement at the LHC. Experiments like ATLAS and CMS calibrate jet energies, muon momenta, electron energies, and more, and the field has been moving quickly to replace traditional methods with ML. If those ML methods are inherently prior-dependent, gains in one context can silently create systematic errors in another. A new-physics search that relies on a calibration derived from a control sample with different kinematics could be quietly, systematically wrong.
There is also a real theoretical gap. Prior-independent simulation-based calibration is solvable, and the Gaussian Ansatz offers a practical path. Prior-independent data-based calibration remains open. The authors are upfront about this, precisely to push the community toward better methods.
ML calibrations for particle physics detectors can secretly inherit the biases of their training data, corrupting downstream measurements. The fix exists for simulation-based calibration but remains an unsolved challenge for data-based methods.
IAIFI Research Highlights
This work applies statistical ML theory to a central problem in experimental particle physics, showing how prior dependence creates concrete, measurable biases in LHC calibrations.
The paper formalizes conditions under which regression-based ML models fail to generalize across distribution shifts, with implications for scientific ML applications where training and deployment distributions differ.
By identifying and partially solving the prior dependence problem in simulation-based jet energy calibration, this work helps protect measurements behind searches for new physics at the LHC.
Prior-independent data-based calibration remains an open challenge the authors hope will motivate new approaches; the full paper is available as [arXiv:2205.05084](https://arxiv.org/abs/2205.05084).
Original Paper Details
Bias and Priors in Machine Learning Calibrations for High Energy Physics
[2205.05084](https://arxiv.org/abs/2205.05084)
["Rikab Gambhir", "Benjamin Nachman", "Jesse Thaler"]
Machine learning offers an exciting opportunity to improve the calibration of nearly all reconstructed objects in high-energy physics detectors. However, machine learning approaches often depend on the spectra of examples used during training, an issue known as prior dependence. This is an undesirable property of a calibration, which needs to be applicable in a variety of environments. The purpose of this paper is to explicitly highlight the prior dependence of some machine learning-based calibration strategies. We demonstrate how some recent proposals for both simulation-based and data-based calibrations inherit properties of the sample used for training, which can result in biases for downstream analyses. In the case of simulation-based calibration, we argue that our recently proposed Gaussian Ansatz approach can avoid some of the pitfalls of prior dependence, whereas prior-independent data-based calibration remains an open problem.