
Anomaly-aware summary statistic from data batches
Authors
Gaia Grosso
Abstract
Signal-agnostic data exploration based on machine learning could unveil very subtle statistical deviations of collider data from the expected Standard Model of particle physics. The beneficial impact of a large training sample on machine learning solutions motivates the exploration of increasingly large and inclusive samples of acquired data with resource efficient computational methods. In this work we consider the New Physics Learning Machine (NPLM), a multivariate goodness-of-fit test built on the Neyman-Pearson maximum-likelihood-ratio construction, and we address the problem of testing large size samples under computational and storage resource constraints. We propose to perform parallel NPLM routines over batches of the data, and to combine them by locally aggregating over the data-to-reference density ratios learnt by each batch. The resulting data hypothesis defining the likelihood-ratio test is thus shared over the batches, and complies with the assumption that the expected rate of new physical processes is time invariant. We show that this method outperforms the simple sum of the independent tests run over the batches, and can recover, or even surpass, the sensitivity of the single test run over the full data. Beside the significant advantage for the offline application of NPLM to large size samples, the proposed approach offers new prospects toward the use of NPLM to construct anomaly-aware summary statistics in quasi-online data streaming scenarios.
Concepts
The Big Picture
Imagine trying to find a single dropped needle in a football stadium. Not by searching the whole field at once, but by dividing it into sections and having teams comb each one simultaneously. When they’re done, you don’t just count how many needles each team found independently. You combine their maps to get a unified picture of where anything unusual was spotted. That’s what this new approach to particle physics anomaly detection does.
At the Large Hadron Collider (LHC), protons smash together billions of times per second, generating torrents of data. The Standard Model of particle physics predicts with high precision what that data should look like. Any new physics beyond the Standard Model, from dark matter to extra dimensions to unknown forces, would show up as a subtle statistical wrinkle. But finding that wrinkle requires searching enormous datasets, and the bigger your sample, the harder it gets computationally.
IAIFI researcher Gaia Grosso has developed a split-and-combine strategy for the New Physics Learning Machine (NPLM), which scans particle collision data for signs of unknown physics. The strategy lets physicists search far larger datasets without compute costs scaling to match. In some cases it actually improves search sensitivity.
Key Insight: Splitting large particle physics datasets into parallel batches and aggregating the learned statistical patterns can detect new physics signals as sensitively as analyzing the entire dataset in one shot, sometimes more so, at a fraction of the computational cost.
How It Works
NPLM is built on the Neyman-Pearson likelihood ratio test, a formal method for deciding whether two collections of data came from the same process or from different ones. The core question: does this dataset look like what the Standard Model predicts, or does it look like something else?
Rather than specifying what that “something else” might be, NPLM trains a neural network to learn the density ratio, a score at every point in the data measuring how much observed collisions differ from a simulated reference dataset. A ratio close to one everywhere means the data matches the Standard Model. A significant deviation signals something anomalous.
The catch is that this neural network needs to train on the full dataset to be maximally sensitive. At the LHC’s scale, that means potentially millions of events across dozens of variables. The split-aggregation approach solves this in four steps:
- Split the full dataset into N batches, each processed by an independent NPLM instance running in parallel
- Each instance learns a local density ratio, a neural network estimate of how the data in that batch deviates from the reference model
- Aggregate those local ratios by computing their weighted average across all batches
- Run the final statistical test on this aggregated, shared hypothesis
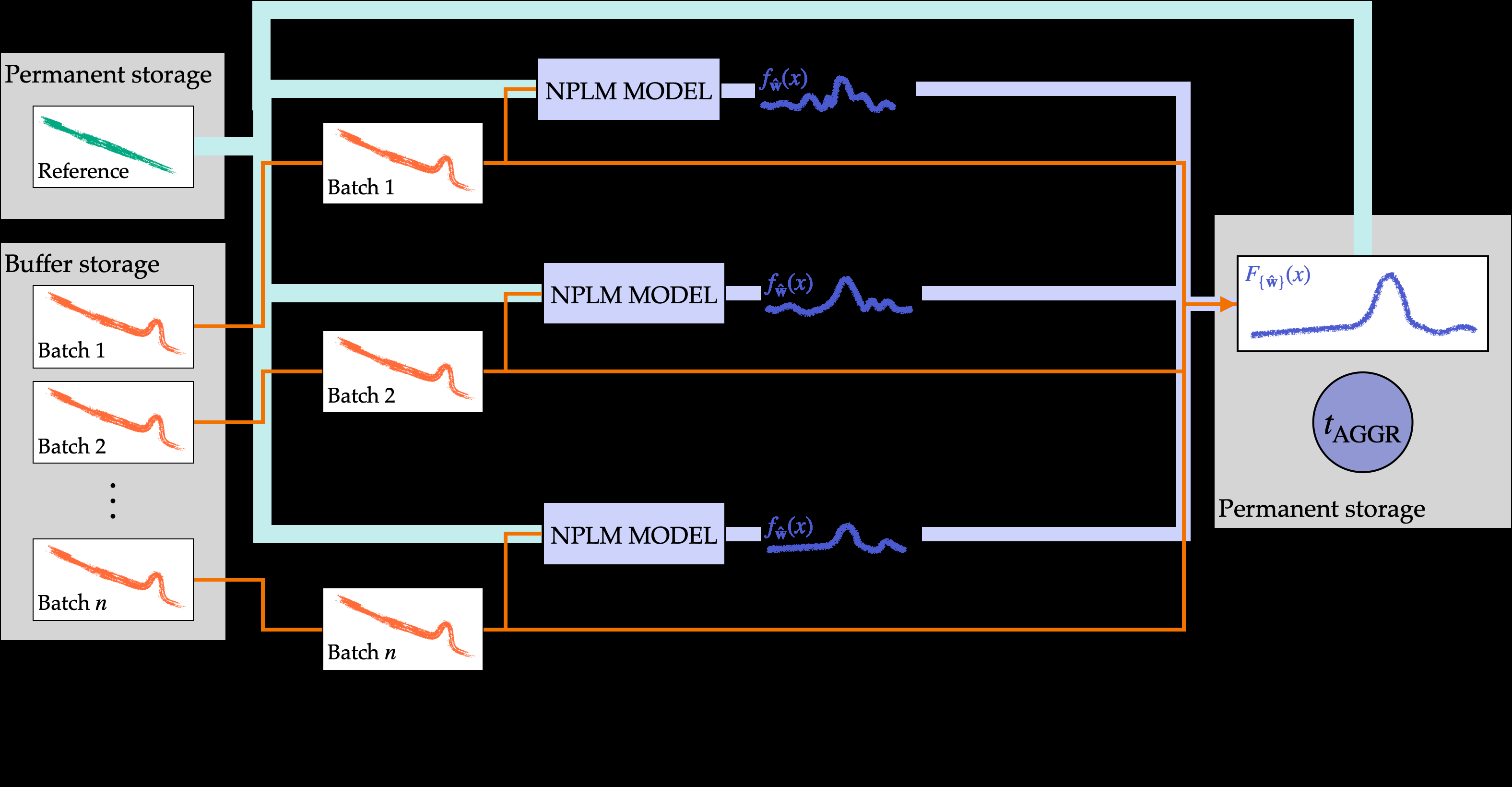
Why not just run N independent tests and combine their p-values? That treats each batch as a completely separate experiment. Aggregation does something smarter: it recognizes that all batches sample from the same underlying physics.
The averaged density ratio acts as a shared hypothesis. Averaging over multiple batch estimates also introduces a regularizing effect, preventing any single model from overfitting to the noise in its particular data slice.
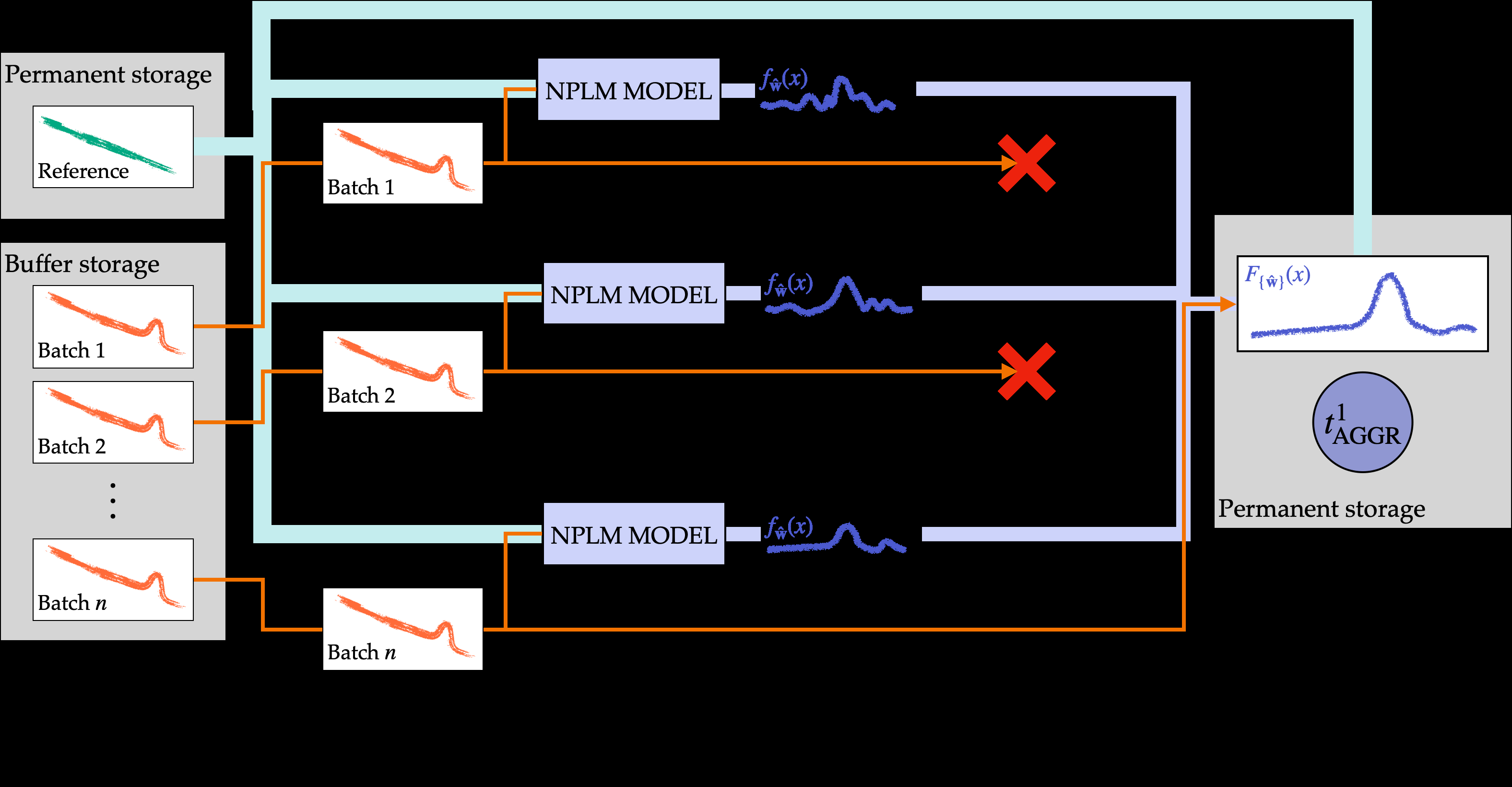
The framework has three operational modes: full aggregation combining all batch models, streaming mode for quasi-online analysis as data arrives continuously, and resource-limited mode that maximizes sensitivity under constrained compute.
Why It Matters
Grosso tested the framework on three progressively harder problems. First, a one-dimensional toy model where the math can be verified analytically. Second, a realistic dimuon final state (a collision outcome producing two muons, heavy cousins of the electron) with around 10,000 events described by 5 variables from a simulated CMS-like detector. Third, a 24-dimensional dataset simulating the CMS Level-1 trigger system, the hardware filter that decides in microseconds which of the billions of collisions per second are worth recording, with over a million events.
For the 5D dimuon problem, aggregation didn’t just match the sensitivity of running NPLM on the full undivided dataset. It outperformed it. This makes sense once you think about regularization: averaging over multiple batch estimates smooths out statistical fluctuations that can confuse a single neural network trained on one large, noisy sample.
On the 24-dimensional CMS trigger dataset, the split-aggregation approach identified injected anomalous signals at various rates while keeping false positive rates under control.
The practical payoff is immediate. Physicists can apply NPLM to datasets they previously couldn’t touch. The LHC generates petabytes of data per year, and even the fraction passing trigger filters is a computational challenge for methods that require joint training on the full sample. Batch parallelization lets researchers work with more inclusive, less filtered data samples, exactly where subtle new physics might be hiding.
The streaming capability may matter even more long-term. NPLM could eventually operate during data collection, not just after. An anomaly-aware summary statistic that updates as new data arrives could flag unusual conditions in real time: new physics, detector malfunctions, unexpected beam conditions.
Right now, offline analysis and online data quality monitoring are handled by entirely different toolchains. This approach could bring the two together.
Signal-agnostic methods like NPLM represent a different philosophy of search. Rather than designing analyses around specific hypothetical particles, they let anomalies surface without being told what to look for. As LHC datasets grow through Run 3 and toward the High-Luminosity LHC upgrade, the need for efficient, assumption-free search tools will only grow with them.
Bottom Line: The batch-aggregation extension of NPLM makes large-scale anomaly detection at particle colliders computationally tractable without sacrificing statistical sensitivity, and in some cases improves it. It also opens a viable path toward real-time anomaly monitoring during data collection.
IAIFI Research Highlights
This work applies distributed computing ideas to a rigorous statistical hypothesis testing framework, making machine-learning-based anomaly detection at the LHC scalable to realistic data volumes.
Aggregating locally trained density ratio estimators produces better generalization than single large-scale training, a concrete example of how ensemble-style neural network combination can outperform monolithic approaches.
By scaling NPLM to millions of events across dozens of dimensions, including CMS Level-1 trigger data, this approach expands the parameter space physicists can search for Standard Model deviations without assuming any specific new-physics hypothesis.
Future directions include fully online deployment for real-time anomaly monitoring during LHC data-taking and extension to higher-dimensional trigger-level datasets; the work is available at [arXiv:2407.01249](https://arxiv.org/abs/2407.01249).