
A Parameter-Masked Mock Data Challenge for Beyond-Two-Point Galaxy Clustering Statistics
Authors
Beyond-2pt Collaboration, :, Elisabeth Krause, Yosuke Kobayashi, Andrés N. Salcedo, Mikhail M. Ivanov, Tom Abel, Kazuyuki Akitsu, Raul E. Angulo, Giovanni Cabass, Sofia Contarini, Carolina Cuesta-Lazaro, ChangHoon Hahn, Nico Hamaus, Donghui Jeong, Chirag Modi, Nhat-Minh Nguyen, Takahiro Nishimichi, Enrique Paillas, Marcos Pellejero Ibañez, Oliver H. E. Philcox, Alice Pisani, Fabian Schmidt, Satoshi Tanaka, Giovanni Verza, Sihan Yuan, Matteo Zennaro
Abstract
The last few years have seen the emergence of a wide array of novel techniques for analyzing high-precision data from upcoming galaxy surveys, which aim to extend the statistical analysis of galaxy clustering data beyond the linear regime and the canonical two-point (2pt) statistics. We test and benchmark some of these new techniques in a community data challenge "Beyond-2pt", initiated during the Aspen 2022 Summer Program "Large-Scale Structure Cosmology beyond 2-Point Statistics," whose first round of results we present here. The challenge dataset consists of high-precision mock galaxy catalogs for clustering in real space, redshift space, and on a light cone. Participants in the challenge have developed end-to-end pipelines to analyze mock catalogs and extract unknown ("masked") cosmological parameters of the underlying $Λ$CDM models with their methods. The methods represented are density-split clustering, nearest neighbor statistics, BACCO power spectrum emulator, void statistics, LEFTfield field-level inference using effective field theory (EFT), and joint power spectrum and bispectrum analyses using both EFT and simulation-based inference. In this work, we review the results of the challenge, focusing on problems solved, lessons learned, and future research needed to perfect the emerging beyond-2pt approaches. The unbiased parameter recovery demonstrated in this challenge by multiple statistics and the associated modeling and inference frameworks supports the credibility of cosmology constraints from these methods. The challenge data set is publicly available and we welcome future submissions from methods that are not yet represented.
Concepts
The Big Picture
Imagine trying to reconstruct a symphony from only the bass line. You’d get the rhythm and some structure, but the harmonics, the countermelodies, the texture that makes it worth hearing? Gone.
Cosmologists have been doing something like this for decades. They map the universe’s large-scale structure using pairwise measurements, counting how often galaxies appear close together at various distances. It works. But the universe encodes far richer information than pairs alone can capture.
As galaxies cluster under gravity over billions of years, the initially near-random distribution of matter develops complex, irregular patterns. Filaments stretch across vast distances. Enormous voids open up between them. Clusters and intricate web-like structures emerge. Pairwise statistics are blind to information encoded in triangles, voids, and higher-order arrangements of galaxies.
With next-generation surveys like DESI, Euclid, and the Rubin Observatory about to deliver an enormous flood of new data, cosmologists need statistical tools that can hear the full symphony.
The Beyond-2pt Collaboration, a large international team, ran a community data challenge to test whether newer “beyond two-point” analysis methods actually work. Can they reliably extract cosmological parameters, the handful of numbers describing the universe’s composition and history, from realistic mock data? Multiple independent methods passed the test, recovering hidden parameters from realistic mock galaxy catalogs. These next-generation statistical tools look ready for real survey data.
How It Works
The challenge had a built-in safeguard called parameter masking. The true cosmological parameters were hidden from participants until after they submitted results, preventing analysts from unconsciously tuning their methods to match expected answers. A double-blind clinical trial, but for cosmological statistics.
The mock data came from high-precision N-body simulations: massive computer calculations that evolve millions of simulated dark matter particles under gravity to produce realistic galaxy distributions. Three flavors of mock catalogs were included. “Real space” catalogs had no observational distortions. “Redshift space” catalogs included the distortions real telescopes see. “Light cone” catalogs mimicked how surveys actually observe the sky across cosmic time.
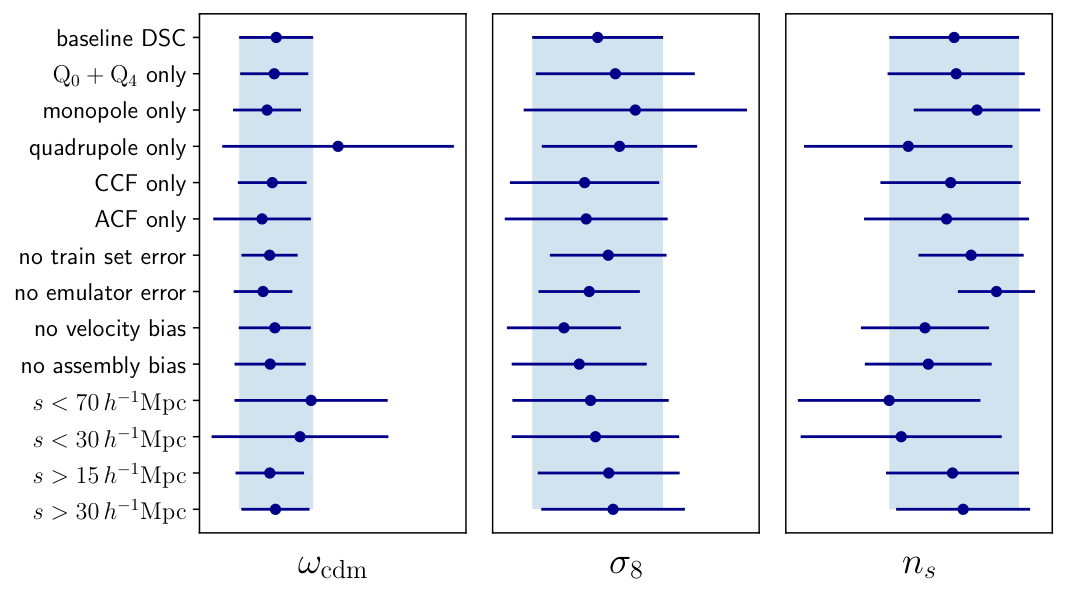
Six analysis methods went head to head, each targeting different aspects of the non-Gaussian information in galaxy clustering:
- Density-split clustering divides the survey volume into regions of different galaxy density and measures clustering in each environment separately
- Nearest neighbor statistics characterize how isolated or crowded each galaxy is relative to its neighbors
- Void statistics extract information from the large empty regions between galaxy filaments
- BACCO power spectrum emulator uses machine learning to interpolate between simulations, extending power spectrum analysis to smaller, nonlinear scales
- LEFTfield performs field-level inference: rather than compressing observations into summary statistics, it analyzes the full three-dimensional galaxy density field directly using Effective Field Theory (EFT), a framework borrowed from particle physics that describes matter clustering at large scales without needing to model every small-scale detail
- Joint power spectrum and bispectrum analyses add the bispectrum (three-point correlations measuring triangular galaxy configurations) using both EFT and simulation-based inference (SBI)
SBI trains neural networks on thousands of simulations to learn the statistical relationship between observations and parameters, bypassing the need for an analytic likelihood function, which becomes intractable for complex statistics. Field-level inference and SBI are among the most ambitious uses of machine learning in cosmology so far.
Why It Matters
The validation matters precisely because it’s hard. Each method involves a long chain of modeling choices: how to simulate galaxy formation, how to handle observational effects, how to build a statistical model, how to sample parameter space. Any link can introduce systematic bias.
Multiple independent methods, built on completely different mathematical frameworks, all recovered the true parameters consistently. That kind of cross-validation gives real confidence that the field is on solid ground.
The challenge also exposed where work remains. Some methods struggled with light-cone geometry or scale cuts. Others showed tension between real-space and redshift-space results that will need further investigation. The collaboration treats this as a living challenge: the dataset is publicly available, and teams can submit results from methods not yet tested.
Next up: realistic survey complications like survey geometry, photometric redshift uncertainties, and the full complexity of galaxy bias (the messy relationship between where galaxies live and where the underlying dark matter actually is). As next-generation surveys come online, these tools will be essential for squeezing every bit of physics out of the data.
IAIFI Research Highlights
This work brings together simulation-based inference and machine learning emulators with statistical cosmology, validating AI-driven methods against traditional analytic approaches in a controlled community challenge.
Simulation-based inference and neural network emulators like BACCO proved competitive with analytic methods. Learned statistical models can recover unbiased cosmological parameters from complex, high-dimensional data.
Recovering ΛCDM parameters, including matter density and the amplitude of density fluctuations, from beyond-two-point statistics directly constrains the physics of dark matter, dark energy, and the growth of large-scale structure.
Future challenge rounds will tackle realistic survey systematics and tighter constraints on extensions to ΛCDM; full results and data are described in [arXiv:2405.02252](https://arxiv.org/abs/2405.02252).
Original Paper Details
A Parameter-Masked Mock Data Challenge for Beyond-Two-Point Galaxy Clustering Statistics
2405.02252
Beyond-2pt Collaboration, :, Elisabeth Krause, Yosuke Kobayashi, Andrés N. Salcedo, Mikhail M. Ivanov, Tom Abel, Kazuyuki Akitsu, Raul E. Angulo, Giovanni Cabass, Sofia Contarini, Carolina Cuesta-Lazaro, ChangHoon Hahn, Nico Hamaus, Donghui Jeong, Chirag Modi, Nhat-Minh Nguyen, Takahiro Nishimichi, Enrique Paillas, Marcos Pellejero Ibañez, Oliver H. E. Philcox, Alice Pisani, Fabian Schmidt, Satoshi Tanaka, Giovanni Verza, Sihan Yuan, Matteo Zennaro
The last few years have seen the emergence of a wide array of novel techniques for analyzing high-precision data from upcoming galaxy surveys, which aim to extend the statistical analysis of galaxy clustering data beyond the linear regime and the canonical two-point (2pt) statistics. We test and benchmark some of these new techniques in a community data challenge "Beyond-2pt", initiated during the Aspen 2022 Summer Program "Large-Scale Structure Cosmology beyond 2-Point Statistics," whose first round of results we present here. The challenge dataset consists of high-precision mock galaxy catalogs for clustering in real space, redshift space, and on a light cone. Participants in the challenge have developed end-to-end pipelines to analyze mock catalogs and extract unknown ("masked") cosmological parameters of the underlying $Λ$CDM models with their methods. The methods represented are density-split clustering, nearest neighbor statistics, BACCO power spectrum emulator, void statistics, LEFTfield field-level inference using effective field theory (EFT), and joint power spectrum and bispectrum analyses using both EFT and simulation-based inference. In this work, we review the results of the challenge, focusing on problems solved, lessons learned, and future research needed to perfect the emerging beyond-2pt approaches. The unbiased parameter recovery demonstrated in this challenge by multiple statistics and the associated modeling and inference frameworks supports the credibility of cosmology constraints from these methods. The challenge data set is publicly available and we welcome future submissions from methods that are not yet represented.